Last time, I blogged about constructing harmonic frames using difference sets. We proved that such harmonic frames are equiangular tight frames, thereby having minimal coherence between columns. I concluded the entry by conjecturing that incoherent harmonic frames are as good for compressed sensing as harmonic frames whose rows were randomly drawn from the discrete Fourier transform (DFT) matrix. In response, Igor Carron commented that recent work of Yves Meyer might be relevant:
These papers are interesting because their approach to compressed sensing is very different. Specifically, their sparse vectors are actually functions of compact support with sufficiently small Lebesgue measure. As such, concepts like conditioning are replaced with that of stable sampling, and the results must be interpreted in the context of functional analysis. The papers demonstrate that sampling frequencies according to a (deterministic) simple quasicrystal will uniquely determine sufficiently sparse functions, and furthermore, the sparsest function in the preimage can be recovered by L1-minimization provided it’s nonnegative.
Igor views these papers as “UFOs” in the literature because they are so different from conventional compressed sensing in so many ways. In this blog entry, I will present Meyer’s results (and proofs) in the analogous context of finite-dimensional harmonic frames, and I’ll make some connections with more familiar approaches.
Specifically, we have the following main result:
Theorem. Take  prime and build a
prime and build a  matrix
matrix 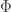 by collecting rows of the
by collecting rows of the  DFT which are indexed by
DFT which are indexed by  . Suppose
. Suppose  is nonnegative and
is nonnegative and 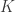 -sparse. If we take measurements of the form
-sparse. If we take measurements of the form  , then is the unique solution of the following program:
, then is the unique solution of the following program:
 .
.
Before proving this theorem, we note that similar results have been reported by Fuchs. In fact, his results apply to a variety of short, fat matrices, including Vandermonde matrices and real Fourier matrices. However, his recovery program enforces nonnegativity as a constraint, and so the Meyer-inspired result above is stronger. Also, our theorem statement is not limited to the particular matrix construction described above, but we’ll focus on this construction for the sake of simplicity.
To prove the above theorem, we first highlight the significance of the all-ones row in , that is, the DFT row indexed by zero. As we will see, this row guarantees two things:
- that is a solution to the program, and
- that every solution to the program is nonnegative.
To see this, consider a competitor  such that
such that  and
and  , and decompose the vector into its positive, negative and imaginary parts:
, and decompose the vector into its positive, negative and imaginary parts:  . Then we have
. Then we have
![\displaystyle{1^*z_+-1^*z_-+i1^*z_i=1^*z=y[0]=1^*x=\|x\|_1\geq\|z\|_1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B1%5E%2Az_%2B-1%5E%2Az_-%2Bi1%5E%2Az_i%3D1%5E%2Az%3Dy%5B0%5D%3D1%5E%2Ax%3D%5C%7Cx%5C%7C_1%5Cgeq%5C%7Cz%5C%7C_1%7D&bg=ffffff&fg=303030&s=0&c=20201002)
 .
.
Since  is real, we know
is real, we know  . Next, rearranging
. Next, rearranging  gives
gives  , but
, but  is nonnegative, and so and
is nonnegative, and so and  are zero. This simplifies our string of inequalities:
are zero. This simplifies our string of inequalities:
 .
.
Since we have equality in the left- and right-hand sides, equality is achieved in both inequalities above. Equality in the first implies that is a minimizer (i.e., a solution to our program), and equality in the second implies that  , and so (i.e., any other solution) is nonnegative since is also zero.
, and so (i.e., any other solution) is nonnegative since is also zero.
Now that we know is a solution to the program, it remains to establish uniqueness. Of course, this would be easy to guarantee if we knew satisfied the null space property (NSP): If  were a solution, then
were a solution, then  is a nontrivial vector in the null space of , but the positive part of this vector is -sparse (since must be nonnegative) and
is a nontrivial vector in the null space of , but the positive part of this vector is -sparse (since must be nonnegative) and  since
since  , violating NSP. Unfortunately, NSP is difficult to demonstrate in general, and in this case, it’s overkill. Since has an all-ones row and every solution of the program is necessarily nonnegative, it’s relatively straightforward to prove the necessity and sufficiency of a certain cone property: that
, violating NSP. Unfortunately, NSP is difficult to demonstrate in general, and in this case, it’s overkill. Since has an all-ones row and every solution of the program is necessarily nonnegative, it’s relatively straightforward to prove the necessity and sufficiency of a certain cone property: that  for every
for every 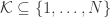 of size
of size  . I won’t bother dwelling on the details of this property; while it might come in handy to prove similar theorems about frames that are not harmonic, it seems easier to exploit the fact that the other rows of come from the DFT in our case.
. I won’t bother dwelling on the details of this property; while it might come in handy to prove similar theorems about frames that are not harmonic, it seems easier to exploit the fact that the other rows of come from the DFT in our case.
We claim it suffices to show that for every of size and every  , there exists a vector
, there exists a vector  with the following properties:
with the following properties:
- it’s nonnegative,
- it’s zero on
 ,
,
- it’s nonzero at
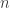 , and
, and
- it’s Fourier transform is supported on the row indices selected, i.e.,
 .
.
Let’s prove our claim: Take to contain the support of . Then for every nonnegative with  , we can take Fourier transforms to get
, we can take Fourier transforms to get
![\displaystyle{0=\langle x,\sigma\rangle=\langle Fx,F\sigma\rangle=\sum_{m=-K}^{K}(Fx)[m]\overline{(F\sigma)[m]}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B0%3D%5Clangle+x%2C%5Csigma%5Crangle%3D%5Clangle+Fx%2CF%5Csigma%5Crangle%3D%5Csum_%7Bm%3D-K%7D%5E%7BK%7D%28Fx%29%5Bm%5D%5Coverline%7B%28F%5Csigma%29%5Bm%5D%7D%7D&bg=ffffff&fg=303030&s=0&c=20201002)
![\displaystyle{=\sum_{m=-K}^{K}(Fz)[m]\overline{(F\sigma)[m]}=\langle Fz,F\sigma\rangle=\langle z,\sigma\rangle}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%3D%5Csum_%7Bm%3D-K%7D%5E%7BK%7D%28Fz%29%5Bm%5D%5Coverline%7B%28F%5Csigma%29%5Bm%5D%7D%3D%5Clangle+Fz%2CF%5Csigma%5Crangle%3D%5Clangle+z%2C%5Csigma%5Crangle%7D&bg=ffffff&fg=303030&s=0&c=20201002) .
.
Since and are nonnegative and orthogonal, they must have disjoint support, i.e., ![z[n]=0](https://s0.wp.com/latex.php?latex=z%5Bn%5D%3D0&bg=ffffff&fg=303030&s=0&c=20201002) . Furthermore, since the choice of was arbitrary, is not supported outside of . Finally since is prime, we know is full spark by Chebotarev’s theorem, meaning it maps -sparse vectors injectively. Thus implies
. Furthermore, since the choice of was arbitrary, is not supported outside of . Finally since is prime, we know is full spark by Chebotarev’s theorem, meaning it maps -sparse vectors injectively. Thus implies  , and so is the unique solution. So how do we ensure that such a always exists?
, and so is the unique solution. So how do we ensure that such a always exists?
One of the key things we have to ensure is that is nonnegative. This can be difficult in general, but Fourier analysis will make it easier in our case. Specifically, we will first pick a vector  and then define entrywise by
and then define entrywise by ![\sigma[n']=|s[n']|^2](https://s0.wp.com/latex.php?latex=%5Csigma%5Bn%27%5D%3D%7Cs%5Bn%27%5D%7C%5E2&bg=ffffff&fg=303030&s=0&c=20201002) for all
for all  . As such, the support of is precisely the support of , but we also need to control the support of the Fourier transform of . By the definition of , we know that
. As such, the support of is precisely the support of , but we also need to control the support of the Fourier transform of . By the definition of , we know that  will be the autocorrelation of
will be the autocorrelation of  , and so the support of will be the set of all differences between members of the support of . Since is to be supported on the selected row entries, and since we generally want to have few rows in our sensing matrix, this means the support of should have a lot of additive structure. This sort of structure is precisely the subject of study in additive combinatorics, and this seems to correspond analogously to Meyer’s definition of model sets.
, and so the support of will be the set of all differences between members of the support of . Since is to be supported on the selected row entries, and since we generally want to have few rows in our sensing matrix, this means the support of should have a lot of additive structure. This sort of structure is precisely the subject of study in additive combinatorics, and this seems to correspond analogously to Meyer’s definition of model sets.
For the particular row indices of this example, namely , it suffices to have supported on  , which has a lot of additive structure, being an arithmetic progression. To establish the existence of such an , we identify our requirements:
, which has a lot of additive structure, being an arithmetic progression. To establish the existence of such an , we identify our requirements:
![s[n']=0](https://s0.wp.com/latex.php?latex=s%5Bn%27%5D%3D0&bg=ffffff&fg=303030&s=0&c=20201002) for all
for all  ,
,![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D&bg=ffffff&fg=303030&s=0&c=20201002) is nonzero, say
is nonzero, say ![s[n]=1](https://s0.wp.com/latex.php?latex=s%5Bn%5D%3D1&bg=ffffff&fg=303030&s=0&c=20201002) , and
, and![(Fs)[n']=0](https://s0.wp.com/latex.php?latex=%28Fs%29%5Bn%27%5D%3D0&bg=ffffff&fg=303030&s=0&c=20201002) for all
for all  .
.
This is a total of linear constraints, and so the -dimensional vector exists if the constraints are linearly independent. Indeed, the square matrix corresponding to these constraints has distinct rows from the identity and DFT matrices, and the determinant is easily shown to be nonzero using Chebotarev’s theorem.
Having proved the main result of this blog entry, I’d like to make a couple of observations. First, there appears to be a disconnect between the harmonic frame constructions suggested by Meyer’s work and the harmonic frames which are known to be good for compressed sensing in general. To be clear, the row entries of Meyer’s harmonic frames have a lot of additive structure, as opposed to randomly drawn row entries which have minimal additive structure. You can tell from the example that the row entries are far from random. The reason behind this contrast might lie in the nonnegativity assumption on the sparse signal. Note that in our proof, the additive structure only played a role when establishing uniqueness of the (nonnegative) solution.
This leads me to my second observation: The nonnegativity assumption appears rather strong. Not only are we able to find a deterministic construction with ease, the construction uses  rows—the number you’d need to guarantee mere injectivity in general. Without the nonnegativity assumption, we are forced to take
rows—the number you’d need to guarantee mere injectivity in general. Without the nonnegativity assumption, we are forced to take  rows for L1-minimization to work; granted, the log factor is small, but it does help to distinguish from Meyer’s result. Of course, there are applications for which nonnegativity is an appropriate assumption, but it would be interesting to find other applications (and determine whether this harmonic construction fits the bill).
rows for L1-minimization to work; granted, the log factor is small, but it does help to distinguish from Meyer’s result. Of course, there are applications for which nonnegativity is an appropriate assumption, but it would be interesting to find other applications (and determine whether this harmonic construction fits the bill).

Great Post, I really liked it!
Hi, Dustin,
Do you have a paper including more details about this topic?
Thanks
Actually, this blog post gives the extent of my work on this project so far. Feel free to ask for any clarification!