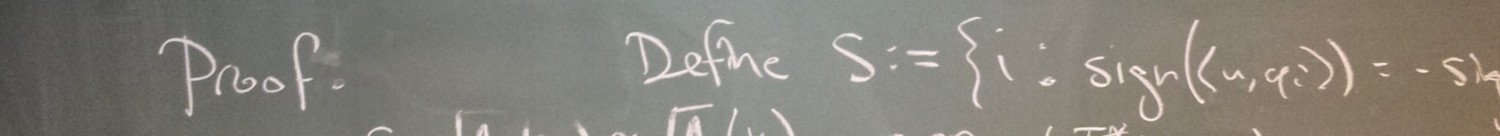
This summer, 3Blue1Brown launched the third installment of the Summer of Math Exposition contest. Every year, I’ve been impressed and inspired by the quality of some of the videos in this contest. Over the last couple of months, I worked with Boris Alexeev and John Jasper to throw our hat in the ring:
I was surprised by how much I learned from this experience. In what follows, I reflect on the process of making this video.
Continue reading Math exposition on YouTube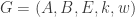 consisting of
consisting of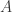 and
and  ,
, ,
,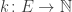 , and
, and .
. denote the set of matrices
denote the set of matrices 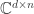 such that
such that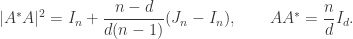
 denotes conjugate transpose,
denotes conjugate transpose,  denotes entrywise squared modulus,
denotes entrywise squared modulus, 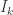 denotes the
denotes the 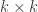 identity matrix, and
identity matrix, and  denotes the
denotes the 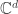 of size
of size 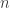 .
.