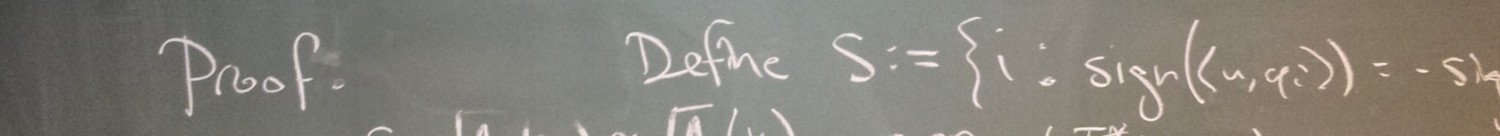
A week ago, I got back from the SIAM SEAS 2012 conference, and I had a lot of fun there. I met with some good friends, and I saw some interesting talks. At the conference, one of my collaborators, Jameson Cahill, talked about a recent paper of ours [UPDATE: Boris indicated to me that he is also an author :)], and I’d like to discuss some of the main ideas in that paper.
It concerns short, fat matrices, say of size 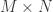



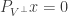
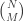
Full spark frames 



For this reason, we seek large families of deterministic full spark frames. To this end, one of the main theorems of our paper generalizes a well-known construction that uses Chebotarev’s theorem; this theorem states that every square submatrix of a prime-ordered discrete Fourier transform (DFT) matrix is invertible, which means any subcollection of rows from such a DFT is necessarily full spark. It is unknown which rows of a general DFT form a full spark frame, but our paper characterizes the full spark choices in the case where the DFT is of prime-power order:
Definition. A subset 

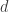
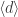



Theorem. Let 
In fact, the above uniform distribution condition is necessary for general 

Another main result of our paper concerns the hardness of testing for full spark. While this problem might feel NP-hard, such a statement requires mathematical proof, and such a proof might be difficult to come by. For example, some might consider the graph isomorphism problem to be intuitively NP-hard, but this is not known to be the case. We prove that testing for full spark is hard for NP under randomized reductions, using the known fact that finding the girth of a transversal matroid is NP-hard. As such, deterministic constructions are special because they guarantee a property which is otherwise difficult to check. If you’ve never read a computational complexity proof before, I recommend you check out the paper.
In the middle of the paper, we also show how full spark Parseval frames are dense in the entire set of Parseval frames, and our techniques are general enough to be used to prove other density results, but I think Jameson is more qualified to discuss this portion of the paper. (Perhaps he should launch a research blog!)
To me, the most interesting part of this paper is the construction of full spark harmonic frames. Certainly, Chebotarev gives that harmonic frames are always full spark when the number of columns is prime, but our result above indicates that something much deeper is going on when this number is not prime. Candes, Rombert and Tao briefly discuss this difficulty in their paper. It remains open which harmonic frames are full spark in the general case. Also, which square submatrices of the DFT are invertible in general?

“As you’d expect, these are particularly easy to build using independent Gaussian entries.”
I love it when textbooks (or blog posts 😉 say things like this about things I don’t understand. Then I can think, “Well duh! I’d have to be an idiot not to expect that. Duh!” It’s a good ego check 😉
Perhaps we should interpret “you’d expect” to mean “you’d expect if you thought about this as much as I have.” 🙂
is it sufficient to say that the full-spark matrices will follow the RIP?
No, full spark matrices do not necessarily have RIP. For example, consider a matrix in which every column comes from the same multivariate Gaussian distribution – say the mean is the first identity basis element and the covariance matrix is a very small multiple of the identity matrix. Then with probability one, this matrix will be full spark, but it will also fail to satisfy RIP with high probability. To see this, notice that it sends the vector of K ones and N-K zeros (whose 2-norm is ) to a vector which is effectively K times the first identity element (whose 2-norm is K – much larger). The reason for this is that full spark is an algebraic condition on the matrix (much like spanning or linear independence) whereas RIP is a more numerical condition (like eigenvalues or condition number).
) to a vector which is effectively K times the first identity element (whose 2-norm is K – much larger). The reason for this is that full spark is an algebraic condition on the matrix (much like spanning or linear independence) whereas RIP is a more numerical condition (like eigenvalues or condition number).
Thanks for your input and time.
I have some more doubt…
“If Phi (MxN) is full spark tight frame matrix and also a vandermonde matrix, can we say that the RIP coefficient (delta) and mutual coherence (mu) will be same (or Phi will follow the (M, mu) RIP)”.
I don’t know why that would be the case. The only time I’ve seen worst-case coherence play a role in RIP is after using the Gershgorin circle theorem, but this is only useful when K is on the order of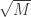 . For more information, check out this paper:
. For more information, check out this paper:
http://arxiv.org/abs/1202.1234