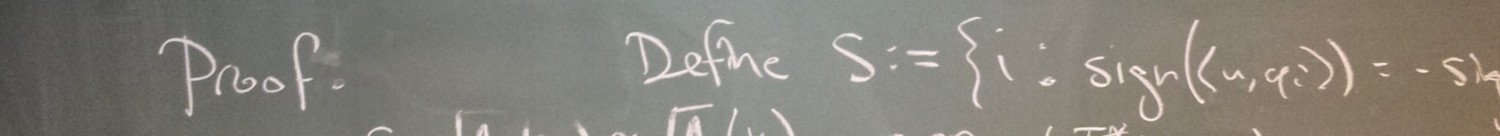
A couple of months ago, Afonso recommended I read this new book by Leslie Valiant. In fact, this book had already been recommended by one of the blogs I follow, so I decided it must be worth the read. The purpose of this blog entry is to document some notes that I took while reading this fascinating book.
Considering the well-established theory of computability (and computational complexity), in hindsight, it seems rather natural to seek a theory of the learnable. What sort of things are inherently learnable, and efficiently so? In order to build a solid theory of learnability, we first need to make some assumptions. Valiant proposes two such assumptions:
1. The Invariance Assumption. Data collected for the learning phase comes from the same source as the data collected for the testing phase. Otherwise, the experiences you learn from are irrelevant to the situations you apply your learning to. In the real world, non-periodic changes in our environment are much slower than our learning processes, and so this is a reasonable assumption for human learning. As for machine learning, the validity of this assumption depends on how well the curriculum is designed.
2. The Learnable Regularity Assumption. In both the learning and testing phases, there are a few regularities available which completely distinguish objects so that efficient categorization is feasible. As humans who learn our environment, our senses are useful because they help us to identify objects, and our brains apply efficient algorithms to determine relationships between these objects, cause and effect, etc. Another way to phrase this assumption is that patterns can be recognized efficiently.
Valiant proposes the following learning model which satisfies both of these assumptions: Suppose you have a universe set 


To this end, Valiant provides the following definition: A concept class 



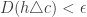



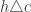

How does PAC learnability incorporate the two learning assumptions above? Implicitly, we are applying the Invariance Assumption by being chiefly concerned with the error 


The name “probably approximately correct” is so peculiar that it requires explanation. The “probably” part relates to the 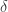

As I see it, PAC learning is a beautiful model for learning, which brings both “good news” and “bad news”:
Good news: The most interesting thing about the PAC learning guarantee is that it is completely independent of the distribution. This means your PAC learning algorithm can make do regardless of the environment, and so PAC learning programmers need not impose distributional assumptions to get the results they need. Overall, PAC learning algorithms are particularly robust to the environment. (Like smoothed analysis, this is an interesting mix of worst- and average-case analysis — PAC seems to focus on the worst of average cases.)
Bad news: At the crux of PAC learning is the restriction to a concept class. Indeed, not all concept classes are PAC learnable — for example, any algorithm that can PAC-learn regular languages can also be used to break RSA (which doesn’t seem possible). As such, to PAC-learn a concept, you must first hope that the concept is a member of a particular class which enables efficient learning. As I interpret it, the restriction to a concept class is inherently necessary to satisfy the Learnable Regularity Asssumption — regardless of the learning model. As such, restricting to a concept class is not as much “bad news” as it is a fact of life. What this means is that somehow our brains are programmed to know which concept classes to restrict to when we learn (or perhaps certain classes are really good at approximating real-world concepts in some way, and we evolved to exploit such classes).
Overall, an exchange is made: We get to drop any assumption on the distribution of data points by accepting an assumption on the concept class. But here’s another way to express this exchange: In many cases (similar to compressed sensing), we might be told that the concept we are learning has certain structure, and if this structure happens to define a PAC learnable concept class, then we can efficiently learn the concept. It turns out that PAC learnability can be established in many cases using VC-dimension arguments (see for example Lecture 9 here).
The book doesn’t just cover learnability. The other two main concepts it approaches are the evolvable and the deducible.
In approaching the evolvable, the goal is to rectify a quantitative discrepancy in the modern theory of evolution — that our current understanding of random mutations and natural selection fails to explain how complex lifeforms came to be in the relatively short amount of time that Earth has existed. Valiant suggests a formalization in which evolution is broken down into time eras, and each era has a target function (think “optimal genome”) which yields maximal fitness — he calls this evolvable target pursuit. In this model, natural selection evaluates functions by how similar they are to the target function over random experiences, and surviving functions are randomly mutated for another round of natural selection. The goal is to converge toward the target function (relative to the probability distribution of experiences) in a reasonable number of generations. Apparently, this model of learning bears similarities with Statistical Query Learning, and a lot of the key results on evolvability seem to follow from the SQ literature accordingly.
In approaching the deducible, the main issue is reasoning with what Valiant called the “theoryless,” specifically, the types of information which have no mathematical basis (e.g., language) — by contrast, the “theoryful” includes mathematics, logic, physics, computer science, etc. He proposed the following example which demonstrates that one has the capacity to reason with the theoryless:
Did Aristotle ever climb a tree? Did he ever have a cell phone?
You might have confidence in your answers to these questions, but where do you derive this confidence? Valiant proposes a model of robust logic to help answer this question as well as a model of working memory that he calls “the mind’s eye.” This portion of the book seemed rather lacking in theory (appropriate, considering it approaches the theoryless), but it certainly illustrated a vision for the future of (artificial) intelligence.

One thought on “Probably Approximately Correct”