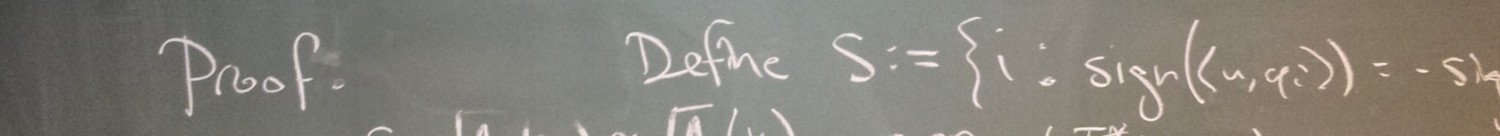
I think most would agree that the way we do math research has completely changed with technology in the last few decades. Today, I type research notes in LaTeX, I run simulations in MATLAB and Mathematica, I email with collaborators on a daily basis, I read the arXiv and various math blogs to keep in the know, and when I get stuck on something that’s a little outside my expertise, I ask a question on MathOverflow. With this in mind, can you think of another step we can take with technology that will revolutionize the way we conduct math research? It might sound ambitious, but the following paper is looking to make one such step:
A fully automatic problem solver with human-style output
M. Ganesalingam, W. T. Gowers
The vision of this paper is to make automated provers extremely mathematician-friendly so that they can be used on a day-to-day basis to help prove various lemmas and theorems. Today, we might use computers as a last resort to verify a slew of cases (e.g., to prove the four color theorem or the Kepler conjecture). The hope is that in the future, we will be able to seamlessly interface with computers to efficiently implement human-type logic (imagine HAL 9000 as a collaborator).
The paper balances its ambitious vision with a modest scope: The goal is to produce an algorithm which emulates the way human mathematicians (1) prove some of the simplest results that might appear in undergraduate-level math homework, and (2) write the proofs in LaTeX. To be fair, the only thing modest about this scope is the hardness of the results that are attempted, and as a first step toward the overall vision, this simplification is certainly acceptable. (Examples of attempted results include “a closed subset of a complete metric space is complete” and “the intersection of open sets is open.”)
The first section of the paper extensively describes the state of the art in automatic theorem proving. My favorite part is the discussion of how a modern automated prover proves Problem 1: “sets which are closed under differences are also closed under inverses.” The discussion is a revealing portrayal of how alien the computer’s thought process really is, and considering the paper’s vision, it illustrates that there’s really a lot of work to be done. This section also discusses the challenges of producing an output with a reader-friendly natural-language format. This helps in clarifying the goal of mimicking human authors (for example, statements like “by modus ponens” should be avoided, despite being the reasoning behind the next line of a proof).
Section 2 starts by systematizing the thought process of human mathematicians. From my perspective, this is interesting in its own right because it helps me to better understand how I think as a mathematician (and perhaps I can exploit that understanding to prove future theorems faster). For the sake of illustration, the authors focus on the result, “a closed subset of a complete metric space is complete.” After sketching a high-level description of a plausible thought process, they proceed to break the thought process down into basic “moves” and they discuss logical reasons for doing these moves. For example:
- If a property is satisfied for all
, then just pick an
- Expand a statement (e.g., replace “
is complete” with “every Cauchy sequence in
- Remove a statement from working memory if it’s already been used enough times (one or two, say).
Note that these last two examples don’t have well-defined criteria for implementing the moves. Indeed, formulating reasonable criteria is the artistic portion of this project, and the authors discuss the heuristics they decided on in subsection 2.4. Actually, the main heuristic seems rather natural: The authors devised a prioritized list of moves such that each successive move should be the highest legal move on the list. As an overarching principle, the authors prioritized moves so that the “safest” legal move is always next. After explaining each move type in gory detail, the authors give an example of the automated prover in action (they prove “the intersection of open sets is open”). More examples of their automated proofs can be found here.
At the end of section 2, the authors also describe how to express the proof moves in human speak. Here, the easiest thing to do is replace computer jargon like 
As many of my readers might be aware, the authors evaluated the quality of their algorithm by making use of Gowers’s Weblog. Specifically, they gave their algorithm 5 test problems, and they gave the same problems to an undergraduate student and to a graduate student. After collecting the proofs, they shuffled them for each problem and asked Gowers’s readership which proofs they preferred and why. (No one suspected that any of the proofs were computer generated!) Later, they revealed that each set had a computer-, undergrad- and graduate-authored proof, and they asked the readers to guess which was which. (The undergrad was commonly confused with the computer!) Click here for the original experiment and here for the results. Overall, this Turing-type test shows that the algorithm they put together works quite well, and furthermore, the entire vision seems rather plausible.
When I read the paper, I couldn’t help but relate it to ideas from Valiant’s book, Probably Approximately Correct. One of the key theses in this book is that it’s better to capture the theoryless (subjects which lack a rigorous backing) by applying a learning process rather than by hard-coding according to a programmer’s intuition. I would think that this philosophy could be leveraged in future iterations of the automated human-like prover (namely, for the “artistic” portions). In particular, it would be interesting if a computer learned the priority of moves exhibited by proofs in the literature. (I suspect that prioritized lists are PAC-learnable.) It seems the lower-hanging fruit on the learning front is to improve the second step of the algorithm by learning from human writing (in the paper, the authors already state their intent to do this).
A small part of me was thinking that the paper might conclude with a punchline-type acknowledgement, revealing that the paper had actually been written by a computer. Alas, that burden is still on us humans (for now).
