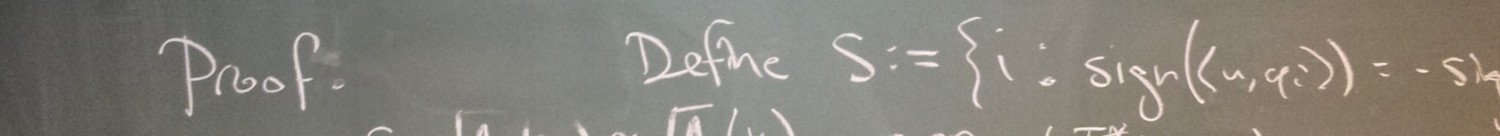
Smoothed analysis was introduced by Spielman and Teng to help explain how the simplex method efficiently solves real-world linear programs despite having a large worst-case complexity. Perhaps a natural analog to the simplex method for semidefinite programs (SDPs) is the Burer–Monteiro factorization method, in which the 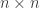

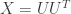

DGM: What is the origin story for this project?
NB: There are a few perspectives to this question, as the team came together in an indirect way. On my end, I met Srinadh in December 2016 at NIPS in Barcelona. Srinadh and Nati Srebro had some (other) low rank problems they wanted to discuss, so we arranged for me to visit them at TTI in Chicago in January 2017. Around that time, Srinadh told me that Praneeth, Prateek and him had figured out one of the lemmas in my previous work with Afonso and Vlad is actually much more general than we make it out to be, specifically applying to quadratically constrained Burer-Monteiro formulations of general SDPs. I was quite surprised and excited about the idea. The other directions Srinadh, Nati and I pushed in Chicago didn’t work out too much at the time, so I traveled back home and that was most of it.
We stayed in touch sparsely. Later that year, in April 2017, I met Praneeth at a great workshop on statistics and optimization in the French Alpes. Praneeth told me more about the project, and welcomed me to the team. From then on, we had skypes between the time-zones of Chicago, Princeton and Bangalore semi-regularly. With all four of us having a number of other commitments, progress was slow. Thankfully, Srinadh was pushing hard and kept us going. A couple months ahead of the COLT deadline, it was decided we should aim to submit what we had, and (from my perspective), that was the pivotal moment when we all started devoting much more time to this project and really get it done. Of course, there’s still more to do.
As for the specific idea to use smoothed analysis, I believe it is Praneeth who pushed in that direction initially, though it may have been as much Prateek and Srinadh. As for me, in parallel, you convinced me this should be the right tool for this problem at a conference in Iowa–I had barely heard of it before. That was an interesting convergence of ideas, where I was hearing from two sides independently that this is direction to go.
SB: Some of the initial work for the project started when I visited Prateek and Praneeth at Microsoft Research in December 2016. We were discussing the results and the proof techniques used in Nicolas’ earlier paper and how we can generalize it to problems without the smoothness assumptions. Later Nicolas joined us and we started looking at the fundamental limitations of these approaches (the existence of spurious local minima), and finally converged onto smoothed analysis based approach.
DGM: Being familiar with Boumal, Voroninski and Bandeira’s paper at NIPS 2016, I’m inclined to think about the low-rank restriction (2) of the SDP (1). Instead, this paper focuses on a penalized version (4) of this restriction. What is the barrier to working with (2) directly?
NB: The Burer-Monteiro formulation (2) is an optimization problem with a quadratic cost function and quadratic equality constraints. One way or another, these constraints must be handled.
Since the goal of the paper is primarily to characterize stationary points, we could have tried to write down first- and second-order necessary optimality conditions for (2), but note that generic quadratic equality constraints define an algebraic variety which, in general, may have kinks and all sorts of difficult geometric features. Because of that, second-order necessary optimality conditions are complex, and difficult to exploit. Part of the difficulty lies in identifying proper constraint qualifications. (By and large, this is the reason why the previous paper with Vlad and Afonso is so much simpler: in that case, the algebraic variety is assumed to be a smooth manifolds, so that there are no kinks.)
Thus, it became clear we had to get rid of the constraints somehow. The traditional approach is to move the constraints to the cost function as some kind of penalty. Augmented Lagrangians or nonsmooth penalties would allow for exact constraint satisfaction, but for starters we decided to focus on quadratic penalties because they are simple and mix well with other components of the problem.
SB: For me looking at (4) is more natural than (2) as to solve constrained problems (2) we use some form of penalized approaches, (either for first order methods like penalty/ALM, or for second order methods like interior point), as computing the projection onto the feasible space of (2) in generally is as hard as solving the problem itself. Quadratic penalty formulation is perhaps the simplest one to approach in this regard, and we focused on presenting the results for this case. However some of our arguments for results early in the paper hold for other penalty formulations including ALM.
DGM: What does it take for an SOSP to exist? Are there general sufficient conditions on 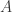
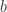
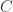
NB: The penalized SDP (3) is a relaxation of the penalized BM formulation (4). Thus, a global optimum of (3), if it has rank at most
I’d have to think about it more carefully as this answer should depend on 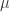

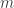
DGM: What is the intuition behind the use of bounded residues in your smoothed analysis result? Is this an artifact of the proof? What are the main ideas in the proof?
NB: That question is spot on. In our smoothed analysis, we aim to make a statement about SOSPs of a penalized and randomly perturbed problem. Whether or not a point
In the proof, we need to make a statement about a quantity which involves both the residues at SOSPs (which depend on
This is unfortunate because eventually much of the technical details of the paper go into bounding residues. I think I speak for all of us when I say that I believe this is an artifact.
On another note, one crucial tool in the proof is a concentration bound published just weeks before we needed it on arXiv by Prof. Hoi H. Nguyen from Ohio State University. That was very lucky, because without it we would not get the correct rate for the rank (namely, that the rank
SB: I consider the idea of using smoothed analysis to show optimality of local minima of non-convex problems to be a key idea in the proof, as the current literature on studying local minima generally make strong assumptions to avoid problems with spurious local minima, and our paper shows that there is another way to get around the problem of spurious local minima, by both perturbation and over parametrization.
On a more technical level, I find the following two ideas we develop in the paper to be potentially useful for a broader class of problems. 1) We show when approximately rank deficient SOSPs are approximately optimal. 2) We also develop new techniques to analyze sub-optimality of any FOSPs, and surprisingly we manage to bound the residues for any approximate FOSPs (this includes saddles and local minima/maxima) of the SDPs we consider.
Adding to what Nicolas said on the concentration bound, Praneeth did have a proof to bound eigenvalues of 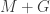
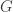
DGM: Do we understand how the optimizer changes when randomly perturbing the objective? This is important for the Max-Cut application, for example.
NB: We haven’t thought about this too much yet, having focused on analyzing the penalized and perturbed problem. Relating approximate SOSPs of that problem to the original SDP (1) is an important aspect of future work we need to do.
SB: We can bound the change in the objective value because of the perturbation, but not the distance between the solutions (unless
Another perspective is that, success of smoothed analysis for a problem suggest that the bad instances are really rare and probably we do not encounter them in practice. So we need perturbation only for analysis and is probably not required to actually solve the problem in practice.
This also brings up an interesting open question- we need perturbation for some worst case problems, but maybe ‘nicer’ problems like Max-Cut do not require it. Is there a way to characterize SDPs with bad low rank local minima?
DGM: Your section on “Conclusions and perspectives” highlights a few interesting directions for future investigation. Is there anything that you’re particularly excited to pursue?
NB: I’m sure my collaborators have different perspectives on what is most urgent. To me, the numerical analysis perspective is crucial, which means I’m most interested in figuring out how all of this applies to the Augmented Lagrangian Method (ALM) that Burer and Monteiro used in their original papers, for good reasons. ALM is just much better than quadratic penalties to enforce constraints, but it comes with a delicate mechanism for the evolution of the penalization weights. We’re on it :).
SB: ALM is definitely something we want to pursue. Another direction that interests me is relaxing the condition on rank, that currently depends on the number of constraints which is required for the worst case, and allow to have smaller rank based on some problem dependent property.
