I’m attending an NSF program review, and Thomas Strohmer gave an awesome talk yesterday. Imagine a scenario in which you are trying to solve a linear inverse problem, but you don’t have complete information about the linear operator. Apparently, this is common when working with small sensors or with high-resolution data. Here’s the problem formulation: You receive
 ,
,
where  is an unknown parameter,
is an unknown parameter, 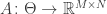 is a known sensing matrix function (i.e., if you knew
is a known sensing matrix function (i.e., if you knew 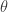 , then you could determine the sensing matrix
, then you could determine the sensing matrix 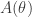 ), and
), and 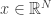 is an unknown signal exhibiting some notion of sparsity or structure. So what are the conditions that allow one to recover and
is an unknown signal exhibiting some notion of sparsity or structure. So what are the conditions that allow one to recover and  from
from 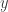 ?
?
In the case where is known, this is simply compressed sensing. Actually, you might call it
- Compressed Sensing 1.0 if is sparse, i.e.,
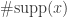 is small, or
is small, or
- Compressed Sensing 2.0 if has low rank (when reshaped into a matrix).
The problem of finding the appropriate parameter for the sensing matrix is called calibration, and we would like systematic approaches for solving this problem (i.e., “self-calibration”). This seems most feasible when 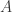 is a linear function of . In this case, each entry of the data
is a linear function of . In this case, each entry of the data ![B_m(\theta,x):=(A(\theta)x)[m]](https://s0.wp.com/latex.php?latex=B_m%28%5Ctheta%2Cx%29%3A%3D%28A%28%5Ctheta%29x%29%5Bm%5D&bg=ffffff&fg=303030&s=0&c=20201002) is a bilinear form, and so it might be helpful to express the inverse problem as finding sparse or structured and such that
is a bilinear form, and so it might be helpful to express the inverse problem as finding sparse or structured and such that
![y[m]=\theta^\top B_m x\qquad \forall m\in\{1,\ldots,M\}](https://s0.wp.com/latex.php?latex=y%5Bm%5D%3D%5Ctheta%5E%5Ctop+B_m+x%5Cqquad+%5Cforall+m%5Cin%5C%7B1%2C%5Cldots%2CM%5C%7D&bg=ffffff&fg=303030&s=0&c=20201002) ,
,
where  is the matrix representation of the bilinear form
is the matrix representation of the bilinear form  . Following a suggestion of Lee Potter, Thomas proposed the following buzzword:
. Following a suggestion of Lee Potter, Thomas proposed the following buzzword:
Compressed Sensing 3.0 — Bilinear optimization problems combined with sparsity and tensor structures.
In the case where is a linear function of , calibration is an instance of CS 3.0. Motivated by real-world calibration problems, Thomas considers the case where belongs to a known subspace and is sparse. For the rest of this blog entry, I will discuss three other instances of CS 3.0 that have been studied to date. One is Peter Jung‘s work, which considers the case where and are both sparse (I summarized this work here). Specifically, 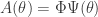 , where
, where 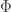 is a measurement matrix and
is a measurement matrix and 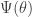 is an unknown sparse combination of dictionaries
is an unknown sparse combination of dictionaries  , i.e,
, i.e,  and is sparse. Apparently, this problem arises from machine-type sporadic communication.
and is sparse. Apparently, this problem arises from machine-type sporadic communication.
Another instance of CS 3.0 was studied by Ali Ahmed, Ben Recht and Justin Romberg (the paper is here). In this case, and both belong to known subspaces, and you receive the circular convolution  — this seems to be a fundamental problem. Let
— this seems to be a fundamental problem. Let  denote the discrete Fourier transform. If we denote
denote the discrete Fourier transform. If we denote 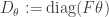 , then we can write , where
, then we can write , where  . To solve this problem, it is more useful to observe the definition of the circular convolution:
. To solve this problem, it is more useful to observe the definition of the circular convolution:
![\displaystyle{(\theta*x)[n]:=\sum_{n'\in\mathbb{Z}_N}\theta[n']x[n-n']}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%28%5Ctheta%2Ax%29%5Bn%5D%3A%3D%5Csum_%7Bn%27%5Cin%5Cmathbb%7BZ%7D_N%7D%5Ctheta%5Bn%27%5Dx%5Bn-n%27%5D%7D&bg=ffffff&fg=303030&s=0&c=20201002) .
.
If we define 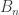 to be the
to be the  matrix such that
matrix such that ![B_n[i,j]=1](https://s0.wp.com/latex.php?latex=B_n%5Bi%2Cj%5D%3D1&bg=ffffff&fg=303030&s=0&c=20201002) when
when  (and zero otherwise), then the received data can be expressed as linear measurements of
(and zero otherwise), then the received data can be expressed as linear measurements of 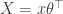 :
:
![y[n]=(\theta*x)[n]=\langle B_n,X\rangle_\mathrm{HS}](https://s0.wp.com/latex.php?latex=y%5Bn%5D%3D%28%5Ctheta%2Ax%29%5Bn%5D%3D%5Clangle+B_n%2CX%5Crangle_%5Cmathrm%7BHS%7D&bg=ffffff&fg=303030&s=0&c=20201002) .
.
Indeed, this can be viewed as another instance of the trace trick:
![y[n]=\theta^\top B_n x=\mathrm{Tr}[\theta^\top B_n x]=\mathrm{Tr}[B_n x\theta^\top]=\langle B_n,X\rangle_\mathrm{HS}](https://s0.wp.com/latex.php?latex=y%5Bn%5D%3D%5Ctheta%5E%5Ctop+B_n+x%3D%5Cmathrm%7BTr%7D%5B%5Ctheta%5E%5Ctop+B_n+x%5D%3D%5Cmathrm%7BTr%7D%5BB_n+x%5Ctheta%5E%5Ctop%5D%3D%5Clangle+B_n%2CX%5Crangle_%5Cmathrm%7BHS%7D&bg=ffffff&fg=303030&s=0&c=20201002) .
.
Leaning on our experience with CS 2.0, the knee-jerk solution is to hunt for the rank-1 matrix 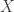 satisfying these linear measurements by minimizing a convexified objective (the nuclear norm
satisfying these linear measurements by minimizing a convexified objective (the nuclear norm  ). Ahmed, Recht and Romberg give conditions on the subspaces for which this relaxation gives exact recovery and stability.
). Ahmed, Recht and Romberg give conditions on the subspaces for which this relaxation gives exact recovery and stability.
Finally, last year found yet another instance of CS 3.0 from Atsushi Ito, Aswin Sankaranarayanan, Ashok Veeraraghavan and Rich Baraniuk (the paper is here). Imagine you take multiple pictures of the same scene, but perhaps you had too much coffee, so every picture is blurred. Can you reconstruct the underlying image? Here, the  th picture is of the form
th picture is of the form  , where
, where  is the blur kernel that describes how the camera moved during the th exposure. As such, you can take
is the blur kernel that describes how the camera moved during the th exposure. As such, you can take 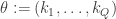 , and attempt to find each under the assumption that it’s sparse, along with , which will have small TV norm since it’s a natural image. This leads to a multi-image deblurring algorithm called BlurBurst (“burst” because you should think of the images as having been taking in rapid succession, or “burst mode”). As you might expect, this algorithm completely destroys image deblurring algorithms that only accept a single blurred image as input (see section 6 of the paper for some stunning comparisons).
, and attempt to find each under the assumption that it’s sparse, along with , which will have small TV norm since it’s a natural image. This leads to a multi-image deblurring algorithm called BlurBurst (“burst” because you should think of the images as having been taking in rapid succession, or “burst mode”). As you might expect, this algorithm completely destroys image deblurring algorithms that only accept a single blurred image as input (see section 6 of the paper for some stunning comparisons).
I’m interested to see more theory and applications of CS 3.0!

2 thoughts on “Compressed Sensing 3.0”