Phase transitions are very common in modern data analysis (see this paper, for example). The idea is that, for a given task whose inputs are random linear measurements, there is often a magic number of measurements 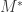 such that if you input
such that if you input 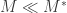 measurements, the task will typically fail, but if you input
measurements, the task will typically fail, but if you input  measurements, the task will typically succeed. As a toy example, suppose the task is to reconstruct an arbitrary vector in
measurements, the task will typically succeed. As a toy example, suppose the task is to reconstruct an arbitrary vector in 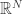 from its inner products with
from its inner products with 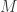 random vectors; of course,
random vectors; of course,  in this case. There are many tasks possible with data analysis, signal processing, etc., and it’s interesting to see what phase transitions emerge in these cases. The following paper introduces some useful techniques for exactly characterizing phase transitions of tasks involving convex optimization:
in this case. There are many tasks possible with data analysis, signal processing, etc., and it’s interesting to see what phase transitions emerge in these cases. The following paper introduces some useful techniques for exactly characterizing phase transitions of tasks involving convex optimization:
Living on the edge: A geometric theory of phase transitions in convex optimization
Dennis Amelunxen, Martin Lotz, Michael B. McCoy, Joel A. Tropp
Along with this paper, I highly recommend watching this lecture by Joel Tropp on the same topic. This blog entry is based on both the paper and the lecture.
Perhaps the most basic application of convex geometry to modern signal processing is that of denoising. Suppose you want to estimate a true signal  from a noisy version
from a noisy version 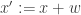 . (Say
. (Say  has iid
has iid  entries.) To do so, you need to leverage additional information about . For example, if you know lies on a shifted subspace, then you can project
entries.) To do so, you need to leverage additional information about . For example, if you know lies on a shifted subspace, then you can project 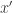 onto that shifted subspace to form an estimate
onto that shifted subspace to form an estimate  , and the portion of the noise that lies in the orthogonal complement of the subspace will be annihilated. This is how least-squares estimation works.
, and the portion of the noise that lies in the orthogonal complement of the subspace will be annihilated. This is how least-squares estimation works.
Now suppose the information you get about the signal is that it’s simple in some sense (e.g., sparse or low-rank). The simplicity of the signal might be expressible in terms of a convex function 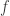 (e.g., the 1-norm or trace norm). So let’s say you’re told that
(e.g., the 1-norm or trace norm). So let’s say you’re told that 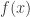 is at most some value
is at most some value 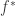 . Then you might denoise by projecting onto the convex set
. Then you might denoise by projecting onto the convex set  of points of value
of points of value 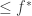 . But how well does this denoiser perform? Say the final estimator is . One way to judge the quality of this estimator is to consider the mean squared error
. But how well does this denoiser perform? Say the final estimator is . One way to judge the quality of this estimator is to consider the mean squared error ![\mathbb{E}[\|\hat{x}-x\|^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5C%7C%5Chat%7Bx%7D-x%5C%7C%5E2%5D&bg=ffffff&fg=303030&s=0&c=20201002) relative to
relative to 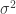 . It has been empirically observed (e.g., here) that the worst-case relative mean squared error in denoising
. It has been empirically observed (e.g., here) that the worst-case relative mean squared error in denoising ![\sup_{\sigma>0}\frac{1}{\sigma^2}\mathbb{E}[\|\hat{x}-x\|^2]](https://s0.wp.com/latex.php?latex=%5Csup_%7B%5Csigma%3E0%7D%5Cfrac%7B1%7D%7B%5Csigma%5E2%7D%5Cmathbb%7BE%7D%5B%5C%7C%5Chat%7Bx%7D-x%5C%7C%5E2%5D&bg=ffffff&fg=303030&s=0&c=20201002) is apparently identical to the phase transition for convex recovery using the same convex function . Recently, Oymak and Hassibi found an important geometric characterization of this worst-case error:
is apparently identical to the phase transition for convex recovery using the same convex function . Recently, Oymak and Hassibi found an important geometric characterization of this worst-case error:
![\displaystyle{\sup_{\sigma>0}\tfrac{1}{\sigma^2}\mathbb{E}[\|\hat{x}-x\|^2]=\delta(\mathcal{D}(f,x))}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csup_%7B%5Csigma%3E0%7D%5Ctfrac%7B1%7D%7B%5Csigma%5E2%7D%5Cmathbb%7BE%7D%5B%5C%7C%5Chat%7Bx%7D-x%5C%7C%5E2%5D%3D%5Cdelta%28%5Cmathcal%7BD%7D%28f%2Cx%29%29%7D&bg=ffffff&fg=303030&s=0&c=20201002) ,
,
where  is the cone generated by points in
is the cone generated by points in 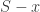 (this is called the descent cone of at ), and
(this is called the descent cone of at ), and 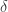 is the statistical dimension, defined by
is the statistical dimension, defined by
![\delta(C):=\mathbb{E}[\|P_C(g)\|^2]](https://s0.wp.com/latex.php?latex=%5Cdelta%28C%29%3A%3D%5Cmathbb%7BE%7D%5B%5C%7CP_C%28g%29%5C%7C%5E2%5D&bg=ffffff&fg=303030&s=0&c=20201002) ;
;
here,  is the projection onto the convex cone
is the projection onto the convex cone 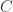 and
and 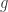 is a vector with iid
is a vector with iid  entries.
entries.
It turns out that statistical dimension is particularly natural as a measure of the size of a cone. For example, a 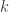 -dimensional subspace has statistical dimension . Also, the statistical dimension has been calculated for various cones of interest, such as the positive semidefinite cone (see Table 4.1 in the paper). Since statistical dimension characterizes the worst-case relative mean-squared error in denoising, and since this error has been empirically observed to be identical to a corresponding phase transition, it is perhaps not surprising that statistical dimension also provably characterizes phase transitions. This is the main result of the paper:
-dimensional subspace has statistical dimension . Also, the statistical dimension has been calculated for various cones of interest, such as the positive semidefinite cone (see Table 4.1 in the paper). Since statistical dimension characterizes the worst-case relative mean-squared error in denoising, and since this error has been empirically observed to be identical to a corresponding phase transition, it is perhaps not surprising that statistical dimension also provably characterizes phase transitions. This is the main result of the paper:
Theorem (Approximate kinematic formula). Fix a tolerance  . Suppose
. Suppose  are closed convex cones, one of which is not a subspace. Draw an
are closed convex cones, one of which is not a subspace. Draw an  orthogonal matrix
orthogonal matrix 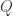 uniformly at random. Then
uniformly at random. Then
![\delta(C)+\delta(K)\leq N-\sqrt{16N\log(4/\eta)}\quad \Longrightarrow \quad \mathrm{Pr}[C\cap QK=\{0\}]\geq1-\eta](https://s0.wp.com/latex.php?latex=%5Cdelta%28C%29%2B%5Cdelta%28K%29%5Cleq+N-%5Csqrt%7B16N%5Clog%284%2F%5Ceta%29%7D%5Cquad+%5CLongrightarrow+%5Cquad+%5Cmathrm%7BPr%7D%5BC%5Ccap+QK%3D%5C%7B0%5C%7D%5D%5Cgeq1-%5Ceta&bg=ffffff&fg=303030&s=0&c=20201002) ,
,
![\delta(C)+\delta(K)\geq N+\sqrt{16N\log(4/\eta)}\quad \Longrightarrow \quad \mathrm{Pr}[C\cap QK=\{0\}]\leq\eta](https://s0.wp.com/latex.php?latex=%5Cdelta%28C%29%2B%5Cdelta%28K%29%5Cgeq+N%2B%5Csqrt%7B16N%5Clog%284%2F%5Ceta%29%7D%5Cquad+%5CLongrightarrow+%5Cquad+%5Cmathrm%7BPr%7D%5BC%5Ccap+QK%3D%5C%7B0%5C%7D%5D%5Cleq%5Ceta&bg=ffffff&fg=303030&s=0&c=20201002) .
.
Now suppose 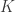 is a subspace of dimension
is a subspace of dimension  . Then
. Then  can be realized as the null space of an
can be realized as the null space of an 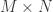 matrix
matrix 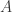 with iid entries. Also, if
with iid entries. Also, if 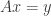 , then is the unique minimizer of
, then is the unique minimizer of  subject to
subject to 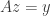 precisely when the null space of trivially intersects the descent cone . As such, this minimization routine reconstructs with a phase transition at
precisely when the null space of trivially intersects the descent cone . As such, this minimization routine reconstructs with a phase transition at 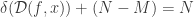 , i.e., at
, i.e., at 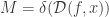 . Indeed, the above result proves the conjecture that identifies this phase transition with the denoising error. And it does so while offering some helpful geometric perspective.
. Indeed, the above result proves the conjecture that identifies this phase transition with the denoising error. And it does so while offering some helpful geometric perspective.
As you might expect, this result finds applications in compressed sensing and random demixing problems, and it also offers some insight into something called random cone programs: How large must be for there to exist an in a fixed cone such that 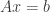 , where
, where 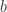 is fixed and has iid entries? Go figure, this also exhibits a phase transition at .
is fixed and has iid entries? Go figure, this also exhibits a phase transition at .
I want to close by noting the similarity between the first part of the approximate kinematic formula and Gordon’s escape through a mesh theorem. It turns out that the statistical dimension of a cone is more or less the square of the Gaussian width of the intersection between and the unit sphere:
 .
.
(See Proposition 10.1 in the paper.) Recall that Gordon’s escape through a mesh theorem says that an 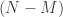 -dimensional subspace hits a set
-dimensional subspace hits a set 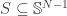 with probability decaying exponentially with
with probability decaying exponentially with 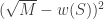 . This corresponds exactly with how, by the approximate kinematic formula, hitting the set exhibits a phase transition at
. This corresponds exactly with how, by the approximate kinematic formula, hitting the set exhibits a phase transition at  , where is the cone generated by . As such, this formula establishes that the escape theorem is tight in some sense.
, where is the cone generated by . As such, this formula establishes that the escape theorem is tight in some sense.


3 thoughts on “Living on the edge: A geometric theory of phase transitions in convex optimization”