Last week, I attended SampTA at Jacobs University in Bremen, Germany. The organizers did a fantastic job, and in this blog entry, I’ll discuss three of the plenary talks that I found particularly interesting.
— Fast algorithms for sparse Fourier transform —
On Tuesday, Piotr Indyk talked about a randomized version of the fast Fourier transform that provides speedups in the case where the desired signal is (nearly) sparse in the frequency domain. His talk was mostly based on this paper, but check out this page for a bigger picture of the research program. To help our intuition, he focused on the case where the Fourier transform is exactly sparse (having at most 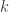 nonzero entries), in which case the number of operations is
nonzero entries), in which case the number of operations is  , where
, where 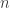 in the dimension of the ambient vector space. Note that this is a substantial improvement over the FFT, which uses
in the dimension of the ambient vector space. Note that this is a substantial improvement over the FFT, which uses  operations. Also note that when is small relative to , this number of operations is actually less than the dimension of the space. As such, the sparse FFT (sFFT) will not even read the entire -dimensional input!
operations. Also note that when is small relative to , this number of operations is actually less than the dimension of the space. As such, the sparse FFT (sFFT) will not even read the entire -dimensional input!
To see how this is even possible, consider the following figure (I took this from these slides):

The picture on the left depicts the given signal, and the picture on the right gives the modulus of its Fourier transform, which in this case is 4-sparse. The graph on the right can be gotten by taking the FFT of the graph on the left, but this takes  steps. Next, consider what happens if you annihilate the portion of the signal after some small time
steps. Next, consider what happens if you annihilate the portion of the signal after some small time  before the -dimensional FFT:
before the -dimensional FFT:

Here, the multiplication operator in the time domain has the effect of convolving the original sparse Fourier transform with the Fourier transform of the boxcar function (i.e., a sinc). In this example, the four highest local maxima in this convolution indicate the support of the Fourier transform, but the Fourier transform still took time. To improve this, view the portion of the time-domain signal that was not annihilated as a -dimensional signal, and take the -dimensional FFT:

Provided divides , then up to scaling, this -dimensional Fourier transform simply samples the -dimensional Fourier transform at frequencies which are regularly spaced by  . As such, we can expect the peaks in this -dimensional function to be within of the peaks in the -dimensional function. You should think of as the number of “bins” — each of the sample points is a representative from a bin (an interval) of size , and part of the job of the reconstruction algorithm is to invert this “hash function.”
. As such, we can expect the peaks in this -dimensional function to be within of the peaks in the -dimensional function. You should think of as the number of “bins” — each of the sample points is a representative from a bin (an interval) of size , and part of the job of the reconstruction algorithm is to invert this “hash function.”
This is the basic idea underlying sFFT. The remainder of his talk addressed three issues:
1. When two of the spikes in the original Fourier transform are too close, the blurred version of the Fourier transform will not distinguish the peaks. To resolve this, pick a random number  which is coprime with , and dilate the original signal by . This will have the effect of dilating the Fourier transform by
which is coprime with , and dilate the original signal by . This will have the effect of dilating the Fourier transform by 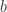 such that
such that  . Considering dilations over
. Considering dilations over  are actually permutations, a random dilation will likely separate the spikes (or at least one of a handful of random dilations will do the trick with high probability). To implement this in the algorithm, take random dilations of the first indices and grab the corresponding entries of the original signal for the -dimensional FFTs. This beautiful trick originated elsewhere in the literature (see this, that, and another).
are actually permutations, a random dilation will likely separate the spikes (or at least one of a handful of random dilations will do the trick with high probability). To implement this in the algorithm, take random dilations of the first indices and grab the corresponding entries of the original signal for the -dimensional FFTs. This beautiful trick originated elsewhere in the literature (see this, that, and another).
2. The Fourier transform of the boxcar function is a sinc, which doesn’t decay particularly fast. As such, you can expect “leakage” to produce false alarms (unless you window the interval to allow for faster decay in the frequency domain). Also, since the frequency domain will be sampled at every points, we might want the Fourier transform of our window to be somewhat uniformly large over an interval of length . With these considerations, a good choice of window is a Gaussian or a Dolph-Chebyshev window function. To implement this in the algorithm, scale the entries by the window function before the FFT. This trick originated in this paper.
3. When you identify a peak in the -dimensional Fourier transform, how do you know which of the corresponding entries in the -dimensional Fourier transform are actually in the support? The trick here is to use modulated dilations instead of just dilations, and then relative phases can be used to determine the proper representative. This is detailed in Lemma 3.4 of the paper.
— Sampling and high-dimensional convex geometry —
The next morning, Roman Vershynin gave an expository talk on how to approach sampling problems with convex geometry. His slides can be found here. He started by reviewing the basic signal recovery problem: You have an unknown signal  in some known set
in some known set  , and you sample according to some known function
, and you sample according to some known function  to get known measurements
to get known measurements  , and the goal is to recover from
, and the goal is to recover from 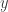 . Here,
. Here, 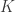 is the signal set, and it represents the prior information you have. The measurement function
is the signal set, and it represents the prior information you have. The measurement function 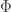 can be linear or nonlinear, and Vershynin discussed both settings, but he first described some modern results in convex geometry.
can be linear or nonlinear, and Vershynin discussed both settings, but he first described some modern results in convex geometry.
If your signal set is not convex, then consider its convex hull — this would be a weaker prior, and so you can certainly work with it. The beauty of focusing on convex sets is that there is a well-established intuition for these, especially asymptotically. In this regime, convex sets should be thought of in terms of the bulk and the outliers. The bulk is essentially a ball that accounts for most of the volume of , whereas the outliers are the “tentacles” that reach from the bulk to the extreme points. The following figure (from Vershynin’s slides) provides a 2-dimensional heuristic of a high-dimensional convex set:

The heuristic is supported by the following result: If satisfies a reasonable “isotropy” condition, namely that 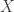 drawn uniformly from has mean zero and covariance
drawn uniformly from has mean zero and covariance 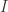 , then the volume of concentrates in the ball centered at the origin of radius
, then the volume of concentrates in the ball centered at the origin of radius  (in fact, we get concentration at the surface of this ball, and the extent of this concentration is the subject of the Thin Shell Conjecture).
(in fact, we get concentration at the surface of this ball, and the extent of this concentration is the subject of the Thin Shell Conjecture).
Not only do outliers make up a tiny fraction of the volume, they are also spatially well separated in the sense that a random subspace will tend to avoid them. More explicitly, a random subspace of codimension 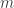 will intersect with diameter
will intersect with diameter  with high probability. Here,
with high probability. Here,  (where
(where 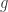 has iid standard Gaussian entries) is the mean width of . If we think of as (essentially) a random vector of length , then
has iid standard Gaussian entries) is the mean width of . If we think of as (essentially) a random vector of length , then  is (essentially) times the expected width of in a random direction:
is (essentially) times the expected width of in a random direction:

Note that mean width is computable in the sense that you can draw at random and determine  by convex optimization; after several realizations, a sample mean will approximate the expectation. Interestingly, the above picture is actually misleading in the sense that the mean width is not driven by the outliers. For example, consider the
by convex optimization; after several realizations, a sample mean will approximate the expectation. Interestingly, the above picture is actually misleading in the sense that the mean width is not driven by the outliers. For example, consider the 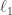 ball, whose bulk has diameter on the order of
ball, whose bulk has diameter on the order of  , and whose outliers each have distance
, and whose outliers each have distance 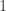 from the origin. In this case, the mean width is on the order of
from the origin. In this case, the mean width is on the order of  . Considering the bulk has mean width
. Considering the bulk has mean width  , we think of mean width as “seeing the bulk” and “ignoring the outliers.”
, we think of mean width as “seeing the bulk” and “ignoring the outliers.”
After building up our intuition for asymptotic convex geometry, Vershynin shifted his focus back to the signal recovery problem. In the linear case, let be multiplication by an  matrix
matrix 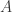 . Then solving for in
. Then solving for in  is ill posed when
is ill posed when  unless is a sufficiently small (i.e., a good prior). In particular, if the shifted nullspace of given by
unless is a sufficiently small (i.e., a good prior). In particular, if the shifted nullspace of given by  has a small-diameter intersection with , then we can pick any representative of this intersection to be our estimate
has a small-diameter intersection with , then we can pick any representative of this intersection to be our estimate  , and this estimate will have small error. Conveniently, if is convex and symmetric about the origin, then the affine subspace of codimension with the largest-diameter intersection with goes through the origin. As such, we can use the fact that this diameter is with high probability to get a guarantee on the quality of our estimate: If I can accept
, and this estimate will have small error. Conveniently, if is convex and symmetric about the origin, then the affine subspace of codimension with the largest-diameter intersection with goes through the origin. As such, we can use the fact that this diameter is with high probability to get a guarantee on the quality of our estimate: If I can accept  error, then I should measure with a Gaussian-random matrix, where
error, then I should measure with a Gaussian-random matrix, where  . This corresponds well with compressed sensing theory: If is the convex hull of
. This corresponds well with compressed sensing theory: If is the convex hull of  -sparse unit vectors in
-sparse unit vectors in 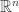 , then
, then  .
.
Before finishing his talk, Vershynin took some time to explain how convex geometry can be used to approach non-linear sampling (based on this paper). The measurement model he considered is  , where is a random matrix and
, where is a random matrix and ![\theta\colon\mathbb{R}\rightarrow[-1,1]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Ccolon%5Cmathbb%7BR%7D%5Crightarrow%5B-1%2C1%5D&bg=ffffff&fg=303030&s=0&c=20201002) is applied to each entry of
is applied to each entry of  . Here, Vershynin requires
. Here, Vershynin requires 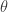 to have the property that if is standard normal, then
to have the property that if is standard normal, then  is correlated with . This way, the nonlinear measurements
is correlated with . This way, the nonlinear measurements  can be viewed as a proxy for the linear measurements
can be viewed as a proxy for the linear measurements  . This measurement model is particularly applicable, for example in single-bit compressed sensing, where
. This measurement model is particularly applicable, for example in single-bit compressed sensing, where  , and in generalized linear models, in which case would be the inverse of the link function. Unfortunately, this model is not applicable to phase retrieval, since
, and in generalized linear models, in which case would be the inverse of the link function. Unfortunately, this model is not applicable to phase retrieval, since ![\mathbb{E}[f(|g|)g]=\mathbb{E}[\mathbb{E}[f(|g|)g|f(|g|)]]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%28%7Cg%7C%29g%5D%3D%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%5Bf%28%7Cg%7C%29g%7Cf%28%7Cg%7C%29%5D%5D%3D0&bg=ffffff&fg=303030&s=0&c=20201002) regardless of
regardless of 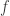 , i.e.,
, i.e.,  is not correlated with .
is not correlated with .
In the special case of single-bit compressed sensing, each measurement tells you which side of a random hyperplane resides. Viewing the random hyperplanes as carving the sphere into cells, then the entire collection of measurements identifies a cell, and to bound the error, it suffices to bound the diameters of the cells. Vershynin called this the “pizza cutting” problem (imagine a spherical pizza…), and he was able to bound the diameters by  for all cells which intersect the prior set
for all cells which intersect the prior set  . As such, you can still get away with
. As such, you can still get away with  measurements even if you’re only given the sign of each measurement.
measurements even if you’re only given the sign of each measurement.
For the general function, can be recovered by a convex program: Find the  which maximizes
which maximizes  . It blows my mind that this recovery program doesn’t depend on the function, i.e., you don’t need to know much about for this to work. As Theorem 1.1 of the paper indicates, they only need to know (a lower bound on) the correlation
. It blows my mind that this recovery program doesn’t depend on the function, i.e., you don’t need to know much about for this to work. As Theorem 1.1 of the paper indicates, they only need to know (a lower bound on) the correlation ![\lambda:=\mathbb{E}[\theta(g)g]](https://s0.wp.com/latex.php?latex=%5Clambda%3A%3D%5Cmathbb%7BE%7D%5B%5Ctheta%28g%29g%5D&bg=ffffff&fg=303030&s=0&c=20201002) to establish a sufficient number of measurements:
to establish a sufficient number of measurements:  .
.
— Robust subspace clustering —
Emmanuel Candes gave the last talk at SampTA, and he discussed recent advances in a very important problem: Given a collection of points, assumed to be noisy samples from a union of low-dimensional subspaces, find the subspaces. If there’s only one subspace, then it could be robustly approximated using principal component analysis (PCA). Otherwise, you would first want to partition the points into subspaces and then do PCA to approximate each one. The main trick is to come up with a way of determining whether points belong to a common subspace. How would you systematically identify points belonging to a common subspace?

Candes’s recent paper on the subject took inspiration from another recent paper, which makes a key observation:
Each point in a subspace can be efficiently represented as a linear combination of other members of that subspace.
For simplicity, let’s first consider the noiseless case, and let ![Y=[y_1\cdots y_N]](https://s0.wp.com/latex.php?latex=Y%3D%5By_1%5Ccdots+y_N%5D&bg=ffffff&fg=303030&s=0&c=20201002) denote the
denote the  points sampled from the union of subspaces. Then the “key observation” motivates the following program:
points sampled from the union of subspaces. Then the “key observation” motivates the following program:
For each  , find the sparsest
, find the sparsest  such that
such that  and
and  .
.
Based on the key observation, the support of implicates other  ‘s that probably lie in a common subspace with
‘s that probably lie in a common subspace with  . Once you have these ‘s, you can build a weighted graph that captures the affinity between points suggested by these supports: For each
. Once you have these ‘s, you can build a weighted graph that captures the affinity between points suggested by these supports: For each  , define the edge weight
, define the edge weight  . Then we expect the components of this graph to correspond to points in a common subspace, and so this is a natural way to cluster the points for PCA.
. Then we expect the components of this graph to correspond to points in a common subspace, and so this is a natural way to cluster the points for PCA.
However, there are a few issues that need to be ironed out. First of all, finding sparsest solutions to linear systems is NP-hard, so we want to relax to L1-minimization, but getting a guarantee for this relaxation will require randomness in 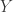 . Furthermore, there needs to be a guarantee for the key observation, and so randomness in could be of use here, too. We should also leave room for the key observation to fail from time to time — certainly, the sparsest will sometimes implicate members of another subspace. As such, instead of expecting pristine connected components in the affinity graph, we should hunt for a more robust version of “components,” i.e., we should partition the graph using spectral clustering. Finally, we also want to account for noise in our sample points, so that will make everything even harder.
. Furthermore, there needs to be a guarantee for the key observation, and so randomness in could be of use here, too. We should also leave room for the key observation to fail from time to time — certainly, the sparsest will sometimes implicate members of another subspace. As such, instead of expecting pristine connected components in the affinity graph, we should hunt for a more robust version of “components,” i.e., we should partition the graph using spectral clustering. Finally, we also want to account for noise in our sample points, so that will make everything even harder.
These issues motivate the following model: Given a collection of subspaces, draw random unit vectors  from each subspace and add iid Gaussian noise
from each subspace and add iid Gaussian noise  to each of these vectors to get the noisy sample:
to each of these vectors to get the noisy sample:  . Since the noise is stochastic, we are compelled to solve the above program for using LASSO, but there are two difficulties: (1) LASSO comes with a regularization factor
. Since the noise is stochastic, we are compelled to solve the above program for using LASSO, but there are two difficulties: (1) LASSO comes with a regularization factor  that might require tuning, and (2) there is noise in the measurement matrix , as opposed to just the vector of measurements (this is a rather atypical setting). For (1), Candes indicated that should be chosen to be around
that might require tuning, and (2) there is noise in the measurement matrix , as opposed to just the vector of measurements (this is a rather atypical setting). For (1), Candes indicated that should be chosen to be around  , where
, where 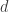 is the dimension of the subspace that (nearly) belongs to. To estimate this dimension, Candes first runs basis pursuit with inequality constraint to solve the above program for and uses the 1-norm of the solution as a proxy for — this, along with running LASSO with the prescribed value of , makes up a two-step procedure that he calls “data-driven regularization.” This procedure and (2) both required substantial theory to produce guarantees (see Section 8 of the paper).
is the dimension of the subspace that (nearly) belongs to. To estimate this dimension, Candes first runs basis pursuit with inequality constraint to solve the above program for and uses the 1-norm of the solution as a proxy for — this, along with running LASSO with the prescribed value of , makes up a two-step procedure that he calls “data-driven regularization.” This procedure and (2) both required substantial theory to produce guarantees (see Section 8 of the paper).
The guarantees they provide are in terms of two parameters. The first is the affinity between subspaces, defined in terms of principal angles:

This notion of affinity is always between 0 and 1; 0 if the subspaces are orthogonal and 1 if one of the subspaces is contained in the other. Note that we don’t need all of the principal angles to be close to 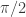 in order for the affinity to be small — in fact, subspaces can intersect nontrivially and still have small affinity. The other parameter of interest is the sampling density of a subspace, defined as the number of (random, unit-norm) samples on that subspace divided by the subspace dimension.
in order for the affinity to be small — in fact, subspaces can intersect nontrivially and still have small affinity. The other parameter of interest is the sampling density of a subspace, defined as the number of (random, unit-norm) samples on that subspace divided by the subspace dimension.
Finally, here’s the guarantee (see Theorems 3.1 and 3.2 in the paper): Suppose the subspaces have dimension  and the noise satisfies
and the noise satisfies  . Run the two-step procedure to find the sparsest such that and . Let
. Run the two-step procedure to find the sparsest such that and . Let  be the -dimensional subspace that (nearly) belongs to. If the affinity between and the other subspaces is
be the -dimensional subspace that (nearly) belongs to. If the affinity between and the other subspaces is  and the sampling density on is
and the sampling density on is  , then with high probability, the support of correctly identifies other members of and
, then with high probability, the support of correctly identifies other members of and  .
.
Note that this guarantee says nothing about the sizes of the nonzero entries of , and so we know nothing about the weights of the graph. Rather, this indicates that the edges tend to make appropriate vertices adjacent, and that the degree of each vertex is proportional to the dimension of the corresponding subspace. Unfortunately, this isn’t enough to produce a guarantee for spectral clustering, and they note this in the paper. In reference to accidentally splitting true clusters, they say:
“This is not what happens and our proofs can show this although we do not do this in this paper for lack of space. Rather, we demonstrate this property empirically.”
Looking at the simulations, they report performance in terms of clustering error. Here, they assume they are told how many subspaces there are, and after running spectral clustering, they determine the proportion of misclassified points. Since the clustering error in their experiments is consistently small (less than 10 percent), I am convinced that the graphs they produce using the two-step procedure are well-suited for spectral clustering. To prove this, I think you’d need to show that the support of corresponds to a “sufficiently random” subset of the other points sampled in — basically, I’d want to somehow guarantee sufficient expansion in the subgraphs induced by the subspaces.
For more information about this work, check out the project page.

One thought on “Three talks from SampTA 2013”