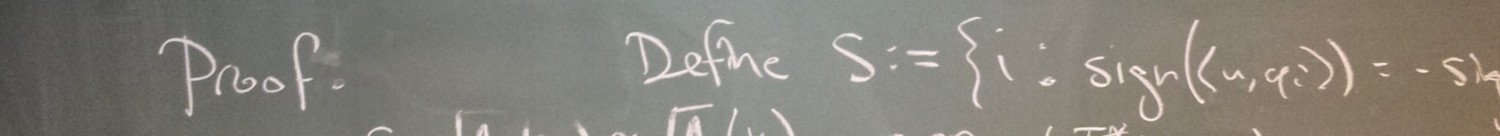
A couple of months ago, I attended a workshop at Oberwolfach (my first!) called “Mathematical Physics meets Sparse Recovery.” I had a great time. I was asked to give the first talk of the week to get everyone on the same page with respect to sparse recovery. Here are the slides from my talk. What follows is an extended abstract (I added hyperlinks throughout for easy navigation):
Compressed sensing has been an exciting subject of research over the last decade, and the purpose of this talk was to provide a brief overview of the subject. First, we considered certain related topics (namely image compression and denoising) which led up to the rise of compressed sensing. In particular, wavelets provide a useful model for images, as natural images tend to be approximated by linear combinations of particularly few wavelets. This sparsity model has enabled JPEG2000 to provide particularly efficient image compression with negligible distortion. Additionally, this model has been leveraged to remove random noise from natural images.
Considering natural images enjoy such a useful model, one may ask whether the model can be leveraged to decrease the number of measurements necessary to completely determine an image. For example, an MRI scan might require up to 2 hours of exposure time, and then the image might be compressed with JPEG2000 after the fact, meaning most of the measurements can be effectively ignored. So is it possible to simply measure the important parts of the image and not waste time in the image acquisition process? This is the main idea underlying compressed sensing, as introduced by Candes, Romberg and Tao and Donoho.
In compressed sensing, one is faced with finding the sparsest vector (i.e., the one with the fewest nonzero entries) which solves an underdetermined linear system. Solving this problem is generally NP-hard, but one may convexify the problem by instead finding the vector with the smallest 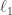
There are many different types of guarantees for compressed sensing. For the scenario in which the sensing matrix is drawn randomly every time a sparse vector is to be measured, one may ask for
To date, there are a few open problems in compressed sensing. First, while there are several random constructions of matrices satisfying the restricted isometry property, explicit constructions are notoriously terrible by comparison (see this and that). This problem of “finding hay in a haystack” is common in combinatorics; for example, there is currently no explicit 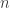
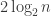
To motivate the next part of my talk, I introduced the Netflix problem. In 2006, Netflix offered a US $1 million prize to improve its movie rating prediction algorithm. Here, the idea is that movie ratings can be organized in a matrix with rows indexed by movies and columns indexed by users. However, since most users have yet to view most movies, Netflix does not have access to most of the entries of this matrix. Fortunately, if we had all of the entries of this matrix, we can assume that principal component analysis would describe the columns of this matrix as essentially lying in a low-dimensional subspace. As such, one might attempt to fill in the blanks by assuming the desired matrix has low rank. This is the motivation behind low-rank matrix completion.
For this problem, one is inclined to find the matrix of minimal rank given the linear measurements available. This is strikingly similar to the problem of compressed sensing, except now we seek to minimize the number of nonzero singular values. As such, the natural relaxation to consider is minimizing the nuclear norm, i.e., the sum of the singular values. Indeed, when completing a low-rank matrix from randomly reported entries, this relaxed optimization is effective provided the low-rank matrix we intend to recover is not localized at any particular entry.
When the linear measurements of the matrix are not entries, but linear combinations of the entries, the problem goes by a different name: low-rank matrix recovery. One important application of this problem is phase retrieval. For this inverse problem, one seeks to recover an input vector from the entrywise absolute value of the output of a known linear operator. By squaring these absolute values, each can be identified as a linear combination of entries of the input vector’s outer product. As such, one can hope to recover this rank-1 outer product by low-rank matrix recovery. To date, there are various guarantees for phase retrieval via low-rank matrix recovery (e.g., 1, 2, 3, 4).
Along the lines of low-rank matrix recovery, there are a few open problems which remain. First, a prominent application of phase retrieval via low-rank matrix recovery is X-ray crystallography, in which the measurements are masked Fourier transforms. Each mask corresponds to an exposure of a small object that one would like to image, but the object is so small that each exposure contributes to its destruction; as such, one would like to image the object with as few exposures as possible. Taking 


The last part of my talk discussed future directions related to compressed sensing. First, given a convolution of a sparse function with a function of rapid decay, one can expect to determine the two functions, especially if the nonzero entries of the sparse function are sufficiently separated. This problem is called blind deconvolution. In general, if you are given a convolution of two functions, each belonging to a known signal class, then you might be able to recover both functions. Taking inspiration from phase retrieval, notice that each entry of the convolution can be expressed as a linear combination of the entries of the outer product of the two functions. As such, one can hope to recover this rank-1 outer product from the convolution using low-rank matrix completion. A related problem is calibration, in which you wish to find the sparsest solution to an underdetermined linear system, but you only know the matrix up to a parameterized family; if the parameterization is linear, then each entry of the output vector is a linear combination of entries from the outer product of the parameter vector and the sparse vector. Recently, there has been a lot of success applying this sort of bilinear compressed sensing to deblur images from multiple blurred exposures. This would be an interesting direction for the community to pursue.

Dustin,
This is a brief but outstanding summary, thank you!
Igor.