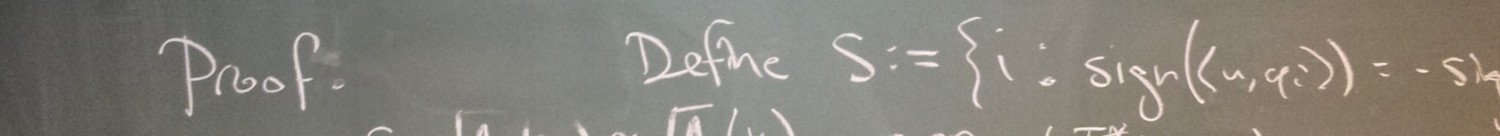
I recently wrote a paper with Afonso Bandeira and Ben Recht, and now it’s on the arXiv (perhaps you heard from Igor). The main idea is dimensionality reduction for classification, but the motivation is different:
Compressed sensing allows for data recovery after compressive measurements, but classification should require even less information.
Since classification is a many-to-one labeling function, we should be satisfied with classifying using compressive measurements in which points of common labels collide. The main concern is to ensure that the measurements distinguish points of differing labels.
To prove this point, we focused on compressively classifying points from full-dimensional sets. This is a very different model from previous studies of compressive classification, all of which focused on low-dimensionality (taking inspiration from compressed sensing). For 2-label classification tasks, the best-case scenario is to have linear separability, which means there exists a hyperplane that separates the two sets of differing labels. This property allows a classifier to simply threshold an inner product with a certain vector to discern which set a given point must belong to. Linear separability is equivalent to having the convex hulls of the two sets be disjoint. This leads to a rather natural question:
The Rare Eclipse Problem. Given a pair of disjoint closed convex sets 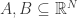
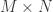

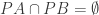
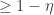
Consider the following illustration of this problem:
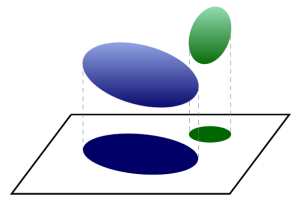
While the two ellipsoids are full-dimensional, there is certainly a 2-dimensional projection that keeps them separated. The rare eclipse problem asks how well a random projection will keep such sets separated.
The answer is rather interesting. Having 
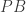
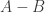
As such, to solve the rare eclipse problem for a given pair of convex sets, it suffices to calculate a Gaussian width. In this paper, we focused on the case of two ellipsoids, as these are somewhat representative of general convex sets by concentration of volume. Intuitively, if two ellipsoids are sufficiently separated, then a random projection will typically fail to collide them, and our main result gives a formula for sufficient separation in terms of the centers and shapes of the ellipsoids. As we detail in the paper, our formula is tighter for more spherical ellipsoids and appears to be not-so-tight for ellipsoids of higher eccentricity.
In the end of the paper, we compare with a popular technique for dimensionality reduction called principal component analysis (PCA). The idea is to center the data and then perform a singular value decomposition to find the leading eigenvectors (principal components) that describe most of the variance in the data. The data is then orthogonally projected onto the span of these principal components. As we identify in the paper, PCA works rather well in some cases, but in others (like certain multiclass instances), it can be less predictable, as it depends on global characteristics of the data. For random projection, the performance for p-label classification can be evaluated in terms of a union bound over all 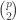

One thought on “Compressive classification and the rare eclipse problem”