Last year, I helped write a couple of chapters in the following book:

Earlier this year, I was invited to become a reviewer for Mathematical Reviews, and my first assignment was to review two chapters from this book. I decided to post my reviews here, and I highly recommend reading these chapters first-hand (both of them are very well written, and they provide fantastic context with the literature).
Quantization and finite frames
Alexander M. Powell, Rayan Saab, Ozgur Yilmaz
This chapter surveys the finite frames literature on quantization. Specifically, it focuses on the following “analysis” formulation:
- First, a vector
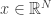 is encoded into frame coeffecients with respect to a frame
is encoded into frame coeffecients with respect to a frame 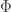 , yielding
, yielding  .
.
- Next, a quantizer
 is applied to
is applied to 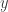 to get
to get  ; here,
; here, 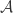 is some finite alphabet.
is some finite alphabet.
- Finally, a decoder
 is applied to
is applied to  to form an estimate
to form an estimate  of the original vector
of the original vector  .
.
With this formulation, the quantization problem is the following: Given some (bounded) signal class  , an
, an  frame , and an alphabet size, design an efficient quantizer and decoder such that the distortion
frame , and an alphabet size, design an efficient quantizer and decoder such that the distortion  is small over
is small over 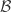 . Throughout, two particular types of quantizers are discussed: the memoryless scalar quantizer (MSQ) and various Sigma-Delta (
. Throughout, two particular types of quantizers are discussed: the memoryless scalar quantizer (MSQ) and various Sigma-Delta ( ) quantizers.
) quantizers.
MSQ individually quantizes each entry of according to the same function:  . While MSQ is particularly efficient, it can produce undesirable levels of distortion. This is indicated by Figure 8.2, which illustrates that the cells of MSQ, namely vectors in
. While MSQ is particularly efficient, it can produce undesirable levels of distortion. This is indicated by Figure 8.2, which illustrates that the cells of MSQ, namely vectors in 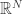 with the same quantized frame coefficients, can be rather large and few. MSQ distortion is more rigorously analyzed in Subsection 8.2.1. Here,
with the same quantized frame coefficients, can be rather large and few. MSQ distortion is more rigorously analyzed in Subsection 8.2.1. Here,  is taken to be a subset of “rounded” frame coefficients in
is taken to be a subset of “rounded” frame coefficients in 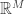 , and a dual frame
, and a dual frame  of is used to reconstruct:
of is used to reconstruct:  . With this decoder, distortion is bounded, but not in terms of the frame’s redundancy, indicating that MSQ fails to adequately exploit this redundancy. In Subsection 8.2.2, MSQ is also evaluated in terms of average distortion
. With this decoder, distortion is bounded, but not in terms of the frame’s redundancy, indicating that MSQ fails to adequately exploit this redundancy. In Subsection 8.2.2, MSQ is also evaluated in terms of average distortion  using a uniform noise model. Specifically, equation (8.15) gives that MSE is proportional to the Frobenius norm of the dual frame used in reconstruction, which in turn is minimized when is the canonical dual of . If we fix the signal dimension
using a uniform noise model. Specifically, equation (8.15) gives that MSE is proportional to the Frobenius norm of the dual frame used in reconstruction, which in turn is minimized when is the canonical dual of . If we fix the signal dimension  and is any unit norm tight frame, then
and is any unit norm tight frame, then  . For comparison, it is known that
. For comparison, it is known that  for a general MSQ decoder. Figure 8.2 illustrates that a linear decoder can be inconsistent in the sense that
for a general MSQ decoder. Figure 8.2 illustrates that a linear decoder can be inconsistent in the sense that  , and so a consistent alternative is proposed in Subsection 8.2.3, which has asymptotically minimal
, and so a consistent alternative is proposed in Subsection 8.2.3, which has asymptotically minimal  .
.
Compared to MSQ, quantization offers less distortion at the price of (slightly) less efficiency. Here, quantizes the frame coefficients in order, each time compensating for any quantization errors incurred with the previous coefficient(s). Specifically, the  th order quantizer iteratively compensates for the previous coefficients; see equations (8.28) and (8.37) for explicit definitions. Again applying a dual frame of as the decoder, Corollary 8.2 bounds the distortion in th order quantization in terms of the operator norm of
th order quantizer iteratively compensates for the previous coefficients; see equations (8.28) and (8.37) for explicit definitions. Again applying a dual frame of as the decoder, Corollary 8.2 bounds the distortion in th order quantization in terms of the operator norm of  , where
, where  is the finite difference operator. While
is the finite difference operator. While  was used to evaluate duals for MSQ reconstruction (and naturally led to the canonical dual),
was used to evaluate duals for MSQ reconstruction (and naturally led to the canonical dual),  is used to evaluate duals for reconstruction, and as Proposition 8.3 reveals, the th order Sobolev dual of minimizes this quantity. In pursuit of an explicit bound on distortion, this quantity is analyzed for Sobolev duals of different types of frames. First, Theorem 8.3 considers a frame path, which is a paramaterized curve in with the property that regularly sampling this curve produces a frame. In this case, sampling at
is used to evaluate duals for reconstruction, and as Proposition 8.3 reveals, the th order Sobolev dual of minimizes this quantity. In pursuit of an explicit bound on distortion, this quantity is analyzed for Sobolev duals of different types of frames. First, Theorem 8.3 considers a frame path, which is a paramaterized curve in with the property that regularly sampling this curve produces a frame. In this case, sampling at 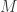 points to get and reconstructing with the th order Sobolev dual incurs distortion
points to get and reconstructing with the th order Sobolev dual incurs distortion  ; when
; when  , this is a substantial improvement to MSQ, even compared to MSQ’s average-case distortion. Next, Theorem 8.4 gives that if is Gaussian random with sufficient redundancy
, this is a substantial improvement to MSQ, even compared to MSQ’s average-case distortion. Next, Theorem 8.4 gives that if is Gaussian random with sufficient redundancy  , then th order Sobolev reconstruction has distortion of the form
, then th order Sobolev reconstruction has distortion of the form  with high probability. Finally, in the cases where is Sobolev self-dual or harmonic, Section 8.5 optimizes the order as a function of redundancy
with high probability. Finally, in the cases where is Sobolev self-dual or harmonic, Section 8.5 optimizes the order as a function of redundancy  to get root-exponential distortion:
to get root-exponential distortion:  . Simulations in Figure 8.6 corroborate these distortion rates, suggesting that exponential decay is not possible (at least with such frames under quantization).
. Simulations in Figure 8.6 corroborate these distortion rates, suggesting that exponential decay is not possible (at least with such frames under quantization).
Finite frames for sparse signal processing
Waheed U. Bajwa, Ali Pezeshki
This chapter surveys the sparse signal processing literature as it relates to finite frames. Overall, the authors describe what can be said about sparse vectors given  , where is $N\times M$ with
, where is $N\times M$ with  and
and 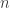 is some noise vector. As an overarching theme, they consider how the pursuit of different types information about imposes different verifiable geometric properties on
is some noise vector. As an overarching theme, they consider how the pursuit of different types information about imposes different verifiable geometric properties on ![\Phi=[\varphi_1\cdots\varphi_M]](https://s0.wp.com/latex.php?latex=%5CPhi%3D%5B%5Cvarphi_1%5Ccdots%5Cvarphi_M%5D&bg=ffffff&fg=303030&s=0&c=20201002) . Specifically, the following matrix parameters are often desired to be small:
. Specifically, the following matrix parameters are often desired to be small:
- spectral norm:

- worst-case coherence:

- average coherence:

- sum coherence:

Intuitively, having any one of these parameters be small ensures that, in some sense, the column vectors of are well distributed in . Throughout, the authors show that when these parameters are small, sparse signal processing can be rather successful. Section 9.2 focuses on how to determine from . Starting with the noiseless setting (where  ), it is established in Theorem 9.1 that every
), it is established in Theorem 9.1 that every 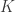 -sparse vector can be recovered by
-sparse vector can be recovered by  minimization provided satisfies the unique representation property: that every subcollection of
minimization provided satisfies the unique representation property: that every subcollection of  columns is linearly independent. Using the Gershgorin circle theorem, it then suffices for to have unit-norm columns and
columns is linearly independent. Using the Gershgorin circle theorem, it then suffices for to have unit-norm columns and  . Unfortunately, this upper bound is
. Unfortunately, this upper bound is  by the Welch bound, whereas drawing the columns of at random from the unit sphere allow for the sparsity level to get as large as
by the Welch bound, whereas drawing the columns of at random from the unit sphere allow for the sparsity level to get as large as  with probability
with probability 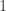 .
.
This reveals a square-root bottleneck that comes with using worst-case coherence; the authors address this bottleneck later in the chapter. First, tractible alternatives to minimization are identified, namely 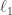 minimization (basis pursuit) and orthogonal matching pursuit, and Theorems 9.4 and 9.5 guarantee recovery, again provided .
minimization (basis pursuit) and orthogonal matching pursuit, and Theorems 9.4 and 9.5 guarantee recovery, again provided .
In the noisy case (where  ), Theorem 9.6 guarantees stable reconstruction using basis pursuit with inequality constraint, provided
), Theorem 9.6 guarantees stable reconstruction using basis pursuit with inequality constraint, provided  . Theorem 9.7 gives a similar guarantee for orthogonal matching pursuit, except the stability also depends on the size of ‘s smallest nonzero entry (this is an artifact of the reconstruction algorithm). In the case where the noise is stochastic, the least absolute shrinkage and selection operator (LASSO) produces a stable estimate of provided (Theorem 9.8), as does a modified version of orthogonal matching pursuit (Theorem 9.9), though this requires the smallest nonzero entry of to be sufficiently large.
. Theorem 9.7 gives a similar guarantee for orthogonal matching pursuit, except the stability also depends on the size of ‘s smallest nonzero entry (this is an artifact of the reconstruction algorithm). In the case where the noise is stochastic, the least absolute shrinkage and selection operator (LASSO) produces a stable estimate of provided (Theorem 9.8), as does a modified version of orthogonal matching pursuit (Theorem 9.9), though this requires the smallest nonzero entry of to be sufficiently large.
To address the square-root bottleneck, the authors note that these reconstruction algorithms perform well when  provided satisfies the restricted isometry property. However, this combinatorial property is particularly difficult to check, and so the authors shift their focus to an alternative notion of performance: Instead of seeking guarantees for all sparse signals simultaneously, they seek to perform well for all but a small fraction of the sparse signals. Section 9.3 is dedicated to such typical guarantees, which use the other matrix parameters above to achieve performance for most -sparse vectors with
provided satisfies the restricted isometry property. However, this combinatorial property is particularly difficult to check, and so the authors shift their focus to an alternative notion of performance: Instead of seeking guarantees for all sparse signals simultaneously, they seek to perform well for all but a small fraction of the sparse signals. Section 9.3 is dedicated to such typical guarantees, which use the other matrix parameters above to achieve performance for most -sparse vectors with  . First, Theorems 9.10 and 9.11 give that and minimization recover most -sparse vectors when , provided
. First, Theorems 9.10 and 9.11 give that and minimization recover most -sparse vectors when , provided  and
and  are small. Next, is taken to be stochastic, and the authors pursue an estimate
are small. Next, is taken to be stochastic, and the authors pursue an estimate  that makes regression error
that makes regression error  small. To this end, Theorem 9.12 gives that LASSO succeeds for most -sparse vectors provided and are small; moreover, the requirement on here is much weaker than those in Theorems 9.10 and 9.11. Also, for most -sparse vectors with sufficiently large nonzero entries, Theorem 9.13 gives that LASSO determines the support of provided and $\mu_\Phi$ are small.
small. To this end, Theorem 9.12 gives that LASSO succeeds for most -sparse vectors provided and are small; moreover, the requirement on here is much weaker than those in Theorems 9.10 and 9.11. Also, for most -sparse vectors with sufficiently large nonzero entries, Theorem 9.13 gives that LASSO determines the support of provided and $\mu_\Phi$ are small.
For each of these typical guarantees, the notion of “most” -sparse vectors has been based on a model in which the support of is drawn randomly, and then the nonzero entries are drawn according to some distribution. The remaining typical guarantees remove the randomness from the nonzero entry values by working for most permutations of all -sparse vectors, and the noise is taken to be stochastic. Theorem 9.14 gives that one-step thresholding determines the support of most -sparse vectors with sufficiently large nonzero entries (relative to  ) provided and
) provided and  are small; the fact that need not be small is an artifact of the algorithm, and the introduction of compensates for the removal of randomness from the signal model. Next, Theorem 9.15 gives that one-step thresholding reconstructs the same sort of -sparse vectors provided , and are small.
are small; the fact that need not be small is an artifact of the algorithm, and the introduction of compensates for the removal of randomness from the signal model. Next, Theorem 9.15 gives that one-step thresholding reconstructs the same sort of -sparse vectors provided , and are small.
The chapter concludes with Section 4, which focuses on sparse signal detection. Here, is either  or
or  , where is stochastic and is -sparse, and the goal is to determine which model holds for a given instance. The authors take the approach of finding the ‘s which are optimal in some sense for
, where is stochastic and is -sparse, and the goal is to determine which model holds for a given instance. The authors take the approach of finding the ‘s which are optimal in some sense for  , and then optimizing these for
, and then optimizing these for  , etc. They first perform this lexicographic optimization in terms of the worst-case signal-to-noise ratio. For this case, Theorem 9.16 gives that the optimizers are equal norm tight frames, Theorem 9.17 gives that the optimizers are Grassmannian equal norm tight frames, and Theorem 9.18 bounds the
, etc. They first perform this lexicographic optimization in terms of the worst-case signal-to-noise ratio. For this case, Theorem 9.16 gives that the optimizers are equal norm tight frames, Theorem 9.17 gives that the optimizers are Grassmannian equal norm tight frames, and Theorem 9.18 bounds the  optimizers in terms of worst-case coherence . Next, they optimize in terms of average-case signal-to-noise ratio; here, Theorem 9.19 gives that optimizers are tight frames, Theorem 9.20 gives that the optimizers minimize sum coherence, and Lemma 9.5 bounds the optimizers in terms of worst-case coherence .
optimizers in terms of worst-case coherence . Next, they optimize in terms of average-case signal-to-noise ratio; here, Theorem 9.19 gives that optimizers are tight frames, Theorem 9.20 gives that the optimizers minimize sum coherence, and Lemma 9.5 bounds the optimizers in terms of worst-case coherence .


One thought on “Two chapters in Finite Frames: Theory and Applications”