I wanted to start this year strong, so I asked Aaron A. Nelson (a master’s student at AFIT) to write a blog entry for me:
Given an ensemble of measurement vectors  , the problem of recovering a signal
, the problem of recovering a signal  from the quadratic data
from the quadratic data  is known as phase retrieval. Naturally, one would like to know when this measurement process is even stable. This issue is tackled in the following paper:
is known as phase retrieval. Naturally, one would like to know when this measurement process is even stable. This issue is tackled in the following paper:
Phase retrieval: Stability and recovery guarantees
Yonina C. Eldar, Shahar Mendelson
Let  where
where  . Then the notion of stability is a statement on the difference
. Then the notion of stability is a statement on the difference  for all
for all  in
in 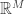 . For this paper, Eldar and Mendelson define the mapping
. For this paper, Eldar and Mendelson define the mapping 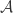 to be stable in a set
to be stable in a set  if there exists a constant
if there exists a constant  such that
such that
 .
.
Notice that this definition is a stronger statement than injectivity, which only requires that  for all in
for all in 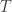 . Basically, Eldar and Mendelson’s notion of stability further says that whenever
. Basically, Eldar and Mendelson’s notion of stability further says that whenever  and
and  are close in the
are close in the 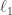 sense, then
sense, then  must also be close to either
must also be close to either 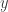 or
or  in the
in the  sense. With this in mind, we see that the constant
sense. With this in mind, we see that the constant 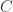 plays an important role in stability: If and are close and is large, then must be really close to either or . Intuitively speaking, the bigger is, the more stable is.
plays an important role in stability: If and are close and is large, then must be really close to either or . Intuitively speaking, the bigger is, the more stable is.
Eldar and Mendelson’s first main stability result (Theorem 2.4) provides an expression for in the special case where  are independent random vectors with identical isotropic, subgaussian distribution:
are independent random vectors with identical isotropic, subgaussian distribution:
 ,
,
with some (large) probability depending only on the constant  . Here,
. Here,  , where
, where 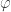 is a random vector with the same distribution as each of the
is a random vector with the same distribution as each of the  ‘s. Also,
‘s. Also,  , where
, where  is the Gaussian complexity of with
is the Gaussian complexity of with  being a Gaussian random vector. Thus, we get more stability if we construct our measurement ensemble (really, the distribution of ) in a way that makes
being a Gaussian random vector. Thus, we get more stability if we construct our measurement ensemble (really, the distribution of ) in a way that makes  large and
large and  small.
small.
Interestingly, the function contains some important information about the ensemble . To be clear, we say has the complement property if for every 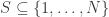 , either
, either  or
or  spans
spans  . It was shown by Balan, Casazza and Edidin that has the complement property if and only if is injective. Notice that has the complement property precisely when
. It was shown by Balan, Casazza and Edidin that has the complement property if and only if is injective. Notice that has the complement property precisely when
 .
.
Furthermore, since the maximum is greater than the average, which in this case tends to be a good proxy for the expected value  , we see that having large intuitively ensures that is “very” injective (i.e., stable). Overall, provides a sort of numerical version of the complement property.
, we see that having large intuitively ensures that is “very” injective (i.e., stable). Overall, provides a sort of numerical version of the complement property.
As for the Gaussian complexity , this is a measure of the best correlation between and a random sequence and can be thought of as the expected width of in a randomly selected direction. For example, if is taken to be an ellipsoid, the complexity measure is a sort of average of the lengths of its semi-principal axes. This makes sense intuitively in the context of Theorem 2.4: If has a smaller width, this forces to be closer to  , thereby making the measurement process inherently more stable.
, thereby making the measurement process inherently more stable.
Considering Theorem 2.4, notice that for a fixed set , the only dependence on the number of intensity measurements  is in . Thus to get stability, we only need to pick so that is sufficiently small. This is precisely what Eldar and Mendelson do – for instance, they determine that stability requires
is in . Thus to get stability, we only need to pick so that is sufficiently small. This is precisely what Eldar and Mendelson do – for instance, they determine that stability requires  measurements when
measurements when  and
and  measurements when is the set of
measurements when is the set of 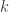 -sparse vectors.
-sparse vectors.
Now consider the mapping  in the presence of noise. That is, let
in the presence of noise. That is, let  be a random noise vector such that the quadratic data for a signal is given by
be a random noise vector such that the quadratic data for a signal is given by  . Typically, the random noise entries are modeled as iid mean zero random variables. Eldar and Mendelson use a
. Typically, the random noise entries are modeled as iid mean zero random variables. Eldar and Mendelson use a  distribution for
distribution for  ; that is, is taken according to the random variable
; that is, is taken according to the random variable 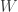 satisfying
satisfying

with  (see Definition 4.2). The goal of phase retrieval is to determine an estimate
(see Definition 4.2). The goal of phase retrieval is to determine an estimate  sufficiently close to an unknown signal
sufficiently close to an unknown signal  when only the measurement ensemble and quadratic data
when only the measurement ensemble and quadratic data  are known. In order to use the results of their stability analysis in this arena, Eldar and Mendelson attempt to minimize the product
are known. In order to use the results of their stability analysis in this arena, Eldar and Mendelson attempt to minimize the product  . As noted by the authors, the appropriate approach to this is to minimize the empirical risk
. As noted by the authors, the appropriate approach to this is to minimize the empirical risk

for some  . However, since is most likely nonzero, even
. However, since is most likely nonzero, even  will be strictly positive; as such, it’s intuitively reasonable to consider to be a decent estimate for if
will be strictly positive; as such, it’s intuitively reasonable to consider to be a decent estimate for if  is not much larger than . For this reason, it is convenient to work with the empirical excess risk
is not much larger than . For this reason, it is convenient to work with the empirical excess risk  . With this, Eldar and Mendelson’s Definition 4.6 says is a good estimate of the signal if
. With this, Eldar and Mendelson’s Definition 4.6 says is a good estimate of the signal if
 ,
,
where  is defined by
is defined by
 .
.
(Note that this implicitly requires to be a bounded set.) The presence of the Gaussian complexity here makes sense since we saw in Theorem 2.4 that stability depends on how small the complexity measure is. Noticing that somewhat resembles from Theorem 2.4, we see that minimizing the empirical excess risk is somehow analogous to finding the value of which ensures stability: just as decreasing made stability stronger in the noiseless case, decreasing makes it tougher to find an estimate satisfying Definition 4.6, thus making any such a stronger estimate. The final main result of the paper (Theorem 4.8), in which the product is bounded above under certain conditions, draws upon this intuition. If is a good estimate for , then there is a constant 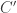 such that
such that

for large enough and a particular ![p\in(1,2]](https://s0.wp.com/latex.php?latex=p%5Cin%281%2C2%5D&bg=ffffff&fg=303030&s=0&c=20201002) . The proof is tedious, but Theorem 4.8 is established by showing that
. The proof is tedious, but Theorem 4.8 is established by showing that  is bounded above by
is bounded above by  and below by . The exact choice of
and below by . The exact choice of 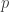 is dependent on the set and the error vector , and is designed to be as close to
is dependent on the set and the error vector , and is designed to be as close to 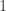 as possible in order to ensure that can be bounded below (see Lemma 4.13). Using this bound, it is possible to determine the necessary number of measurement vectors to guarantee stability. For instance, Eldar and Mendelson use Theorem 4.8 to show that stability occurs with
as possible in order to ensure that can be bounded below (see Lemma 4.13). Using this bound, it is possible to determine the necessary number of measurement vectors to guarantee stability. For instance, Eldar and Mendelson use Theorem 4.8 to show that stability occurs with  measurements when is the unit sphere and
measurements when is the unit sphere and  measurements when is the set of -block-sparse vectors with blocks of size
measurements when is the set of -block-sparse vectors with blocks of size 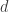 and unit norm.
and unit norm.
Theorem 4.8 is particularly useful because it does not assume anything about how the estimate is determined. Instead, suppose you have a reasonable routine to make the empirical risk small. If you have some idea about the size of the noise , you can use this as a proxy for . Then if your routine made the empirical risk sufficiently small compared to , Theorem 4.8 guarantees that the corresponding estimate is reasonable in some sense.

