Yesterday, I got back from the February Fourier Talks 2013 at the University of Maryland, and I wanted to share a bit of what I learned there. Specifically, the weekend was devoted to a workshop on Phaseless Reconstruction, which is particularly relevant to my research, but some of my colleagues were unable to attend. This blog post is intended to keep everyone in the loop.
The workshop effectively started on Friday night, when Thomas Strohmer gave the Norbert Wiener Colloquium on phase retrieval. His talk was very similar to the one he gave at Vienna, but it seemed to have more bells and whistles that would appeal to a wider audience. As such, not only did his talk set a tone for the workshop, it also got a larger section of the community interested in the phase retrieval problem. The most exciting news in this talk was a shout-out he made to a new paper on the arXiv by Bernhard G. Bodmann and Nathaniel Hammen, which provides the first known construction of  measurement vectors in
measurement vectors in 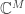 that lend injective intensity measurements for every
that lend injective intensity measurements for every 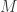 (this is conjectured to be the smallest possible ensemble with this property). Specifically, the proof of this result is given on page 3 of the paper (only one page!), but this brevity seems to come at the price of clarity – at least in my initial attempts to parse the proof. Regardless, it’s exciting to witness this sort of pure-math-type progress on phase retrieval.
(this is conjectured to be the smallest possible ensemble with this property). Specifically, the proof of this result is given on page 3 of the paper (only one page!), but this brevity seems to come at the price of clarity – at least in my initial attempts to parse the proof. Regardless, it’s exciting to witness this sort of pure-math-type progress on phase retrieval.
Saturday morning was kicked off by David Gross, who spoke about matrix completion “with some help from quantum mechanics.” He used the Netflix problem as motivation, and then he described “everything you need to know about quantum mechanics,” which is partly contained in one of my blog entries. The main idea is you want to determine a density operator 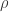 , which is simply a positive semidefinite matrix with unit trace, and the available measurements have the form
, which is simply a positive semidefinite matrix with unit trace, and the available measurements have the form ![\mathrm{Tr}[\rho B]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BTr%7D%5B%5Crho+B%5D&bg=ffffff&fg=303030&s=0&c=20201002) , where
, where  is a self-adjoint matrix (called an observable). This inverse problem is referred to as quantum density estimation, and in many cases (like quantum information processing), you are given even more information about : that it has rank 1 (such ‘s are called pure states). Note that quantum density estimation is a generalization of the Netflix problem over self-adjoint matrices, since you can pick out the real and imaginary parts of each matrix entry with a measurement of the form . This also serves as a generalization of phase retrieval, since
is a self-adjoint matrix (called an observable). This inverse problem is referred to as quantum density estimation, and in many cases (like quantum information processing), you are given even more information about : that it has rank 1 (such ‘s are called pure states). Note that quantum density estimation is a generalization of the Netflix problem over self-adjoint matrices, since you can pick out the real and imaginary parts of each matrix entry with a measurement of the form . This also serves as a generalization of phase retrieval, since ![\mathrm{Tr}[\rho B]=|\langle x,\phi\rangle|^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BTr%7D%5B%5Crho+B%5D%3D%7C%5Clangle+x%2C%5Cphi%5Crangle%7C%5E2&bg=ffffff&fg=303030&s=0&c=20201002) if
if  and
and  (this is precisely the idea behind PhaseLift). After noting these relationships, David discussed his state-of-the-art results on trace minimization for quantum density estimation, which are captured in this paper. The main assumption underlying his result is that the collection of observables is “incoherent” with the measured density operator – here, it suffices for the observables to have small operator norm (which the observables in the Netflix problem have). The proof is rather short compared to its (less general) predecessor from Candes and Tao, and David credits his use of ideas from quantum mechanics that are slowly spreading to other communities. He identified two key pieces of his proof: an aptly named “golfing scheme” which is an iterative random process that provably converges to a certain certificate, and a matrix version of the Bernstein inequality (see Theorem 6 of his paper). He concluded his talk with a particularly nice bit of intuition related to PhaseLift’s use of matrix completion for phase retrieval. Specifically, Holder’s inequality (with
(this is precisely the idea behind PhaseLift). After noting these relationships, David discussed his state-of-the-art results on trace minimization for quantum density estimation, which are captured in this paper. The main assumption underlying his result is that the collection of observables is “incoherent” with the measured density operator – here, it suffices for the observables to have small operator norm (which the observables in the Netflix problem have). The proof is rather short compared to its (less general) predecessor from Candes and Tao, and David credits his use of ideas from quantum mechanics that are slowly spreading to other communities. He identified two key pieces of his proof: an aptly named “golfing scheme” which is an iterative random process that provably converges to a certain certificate, and a matrix version of the Bernstein inequality (see Theorem 6 of his paper). He concluded his talk with a particularly nice bit of intuition related to PhaseLift’s use of matrix completion for phase retrieval. Specifically, Holder’s inequality (with 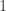 – and
– and 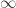 -norms) gives us that sparse and spread vectors are incoherent with each other. As such, it makes intuitive sense that observables with small operator norm (“spread” spectrum) are incoherent with density operators of low rank (“sparse” spectrum). However, PhaseLift specifically uses rank-1 observables, thereby failing to be incoherent with the rank-1 signal (at least through the Holder argument). He credits the use of randomness for allowing PhaseLift to overcome this difficulty, but he also proposed other trade-offs or restrictions to allow coherence arguments to suffice.
-norms) gives us that sparse and spread vectors are incoherent with each other. As such, it makes intuitive sense that observables with small operator norm (“spread” spectrum) are incoherent with density operators of low rank (“sparse” spectrum). However, PhaseLift specifically uses rank-1 observables, thereby failing to be incoherent with the rank-1 signal (at least through the Holder argument). He credits the use of randomness for allowing PhaseLift to overcome this difficulty, but he also proposed other trade-offs or restrictions to allow coherence arguments to suffice.
Next, Philip Schniter described what he calls compressive phase retrieval – that is, phase retrieval with a sparsity prior. (I just took a moment to think of a pun based on the corresponding acronym, but the best I could do is “breathed new life, yada yada yada.”) Similar to compressed sensing, CPR promises to enable one to take far fewer intensity measurements than the dimension of the signal space, and yet still allow for signal reconstruction. He noted a couple of existing algorithms for CPR-based reconstruction, but found them to either be prone to local minima or devastatingly slow. In this light, he introduced generalized approximate message passing (GAMP), which is much faster than a leading competitor, but he noted that GAMP appears to require some randomness in the measurement ensemble. I was personally struck by a suggestion he made with an empirical phase transition he presented for GAMP: Imagine running simulations to see how many noisy linear measurements are needed in dimension 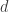 to make reconstruction error smaller than a certain threshold. Since you’re given the phase in this case, you might use L1 minimization to do the reconstruction. Now run the same simulations, except this time throw away the phase and run GAMP. Philip showed that the phase transition for GAMP occurs at approximately
to make reconstruction error smaller than a certain threshold. Since you’re given the phase in this case, you might use L1 minimization to do the reconstruction. Now run the same simulations, except this time throw away the phase and run GAMP. Philip showed that the phase transition for GAMP occurs at approximately  times the number of measurements as in the first case (he called this first case the “phase oracle”). This is particularly interesting because approximately
times the number of measurements as in the first case (he called this first case the “phase oracle”). This is particularly interesting because approximately  intensity measurements are necessary and sufficient for injectivity in the complex case (with no sparsity prior), whereas linear measurements also do the trick (by linear algebra). Apparently, this factor of has a bigger footprint in phase retrieval than I realized, and it would be nice to have a deeper theoretical understanding of this. He then went into some detail to describe how GAMP actually works. The main idea is Bayesian inference with a sparsity prior (i.e., each entry is
intensity measurements are necessary and sufficient for injectivity in the complex case (with no sparsity prior), whereas linear measurements also do the trick (by linear algebra). Apparently, this factor of has a bigger footprint in phase retrieval than I realized, and it would be nice to have a deeper theoretical understanding of this. He then went into some detail to describe how GAMP actually works. The main idea is Bayesian inference with a sparsity prior (i.e., each entry is 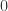 with probability
with probability  and Gaussian with probability
and Gaussian with probability 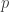 ), but solving for posteriors is hard, so belief propagation is used. Specifically, GAMP passes probability density functions to different nodes, but central limit theorem-type approximations are leveraged to keep the messages simple (just means and variances of Gaussians). He also described EM-turbo-GAMP, a version of which seems to have made an appearance or two on Nuit Blanche. This extension allows you to learn more exotic priors than just sparsity. Interesting stuff.
), but solving for posteriors is hard, so belief propagation is used. Specifically, GAMP passes probability density functions to different nodes, but central limit theorem-type approximations are leveraged to keep the messages simple (just means and variances of Gaussians). He also described EM-turbo-GAMP, a version of which seems to have made an appearance or two on Nuit Blanche. This extension allows you to learn more exotic priors than just sparsity. Interesting stuff.
After lunch, I talked a bit about some work I did recently with Afonso S. Bandeira, Jameson Cahill, and Aaron A. Nelson, but I’ll save the details for a future blog post. I also discussed phase retrieval with polarization (a shorter version of my talk in Vienna), and concluded with some recent polarization-based results I got with Afonso and Yutong Chen (which I’ll blog about as soon as we have something written up).
Xiaodong Li was the next speaker. I had read some of Xiaodong’s work before – he leveraged different concentration inequalities to prove that for a randomly drawn measurement ensemble, PhaseLift is stable for all signals simultaneously, even if the number of measurements is linear in the signal dimension (this amounts to a double improvement over the previous PhaseLift iteration). This was not the subject of his talk, however. Instead, Xiaodong introduced Sparse PhaseLift, which like GAMP, is a routine to perform compressive phase retrieval. Here, the main result is that  intensity measurements are necessary and sufficient for Sparse PhaseLift to successfully reconstruct
intensity measurements are necessary and sufficient for Sparse PhaseLift to successfully reconstruct 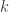 -sparse signals. He noted that this is directly analogous to the compressed sensing regime, since
-sparse signals. He noted that this is directly analogous to the compressed sensing regime, since 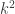 is the sparsity level of the sparse signal’s outer product (the lifted signal).
is the sparsity level of the sparse signal’s outer product (the lifted signal).
Concluding the first day of the workshop, Laurent Demanet presented some work on seismic/ultrasound imaging. The main idea is you want to image stuff underground, so you shoot signals down and listen for a return. But you have the luxury of shooting signals from multiple transmitters and listening with multiple receivers. With this setup, you can choose to ignore the waveforms  you get from different transmitters and receivers, and instead focus on combinations
you get from different transmitters and receivers, and instead focus on combinations  . These combinations are arguably more telling of the features below, and there is apparently some precedent for this in MIMO radar. Laurent told a story about how these combinations were actually used to identify pressure changes in some volcano, which prompted officials to evacuate nearby locations – this happened two weeks before an eruption, thereby saving many lives. Having established the significance of this approach, Laurent proceeded to explain how he proposes to integrate the combinations
. These combinations are arguably more telling of the features below, and there is apparently some precedent for this in MIMO radar. Laurent told a story about how these combinations were actually used to identify pressure changes in some volcano, which prompted officials to evacuate nearby locations – this happened two weeks before an eruption, thereby saving many lives. Having established the significance of this approach, Laurent proceeded to explain how he proposes to integrate the combinations  into an estimate. Here, he leveraged ideas from PhaseLift to convert a quartic objective function into a convex objective with a positive-semidefinite constraint. He also applied the polarization trick and angular synchronization to match the ‘s from the combinations . To make this step work, he actually requires a connected graph with loops – it wasn’t immediately clear to me where this requirement comes from, but I plan to find out when the paper is finished. After the ‘s are estimated, he uses Douglas-Rachford splitting to perform interferometric waveform inversion (apparently, this part of the problem is well understood by now). It’s cool to see both the polarization trick and angular synchronization getting some mileage for a completely different application. I wonder how early we’ll be able to predict volcanic eruptions now. 🙂
into an estimate. Here, he leveraged ideas from PhaseLift to convert a quartic objective function into a convex objective with a positive-semidefinite constraint. He also applied the polarization trick and angular synchronization to match the ‘s from the combinations . To make this step work, he actually requires a connected graph with loops – it wasn’t immediately clear to me where this requirement comes from, but I plan to find out when the paper is finished. After the ‘s are estimated, he uses Douglas-Rachford splitting to perform interferometric waveform inversion (apparently, this part of the problem is well understood by now). It’s cool to see both the polarization trick and angular synchronization getting some mileage for a completely different application. I wonder how early we’ll be able to predict volcanic eruptions now. 🙂
For the second (and last) day of the workshop, Boaz Nadler started us off with his work on vectorial phase retrieval (VPR). Here, he exploits the fact that physical systems often let you measure several signals and their interference. For example, in holography, you can measure  along with
along with  , where
, where 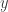 is some known reference signal, and this interference can be used to tease out a lot more information about
is some known reference signal, and this interference can be used to tease out a lot more information about  . In VPR, Boaz doesn’t let you know what is, but instead treats it as another signal to reconstruct. Here, you are given ,
. In VPR, Boaz doesn’t let you know what is, but instead treats it as another signal to reconstruct. Here, you are given , 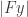 , and
, and  , with the task of determining and – and apparently, this setup is physically realizable. Unfortunately, VPR doesn’t always have a unique solution, considering and don’t give much additional information when and are scalar multiples of each other. As such, and need to be independent in some sense. To this end, Boaz introduces the notion of spectral independence, which says that the
, with the task of determining and – and apparently, this setup is physically realizable. Unfortunately, VPR doesn’t always have a unique solution, considering and don’t give much additional information when and are scalar multiples of each other. As such, and need to be independent in some sense. To this end, Boaz introduces the notion of spectral independence, which says that the  -transforms of and have no common roots. Amazingly, spectral independence completely characterizes VPR uniqueness, at least in the case where the supports of and lie in a common contiguous half of the entries. In this case, reconstruction can be implemented by a polarization trick. Noise robustness seems to be a much harder problem. To address this, Boaz considers a reasonable noise model for his application, and notes that the likelihood function is not convex and thus difficult to maximize (he could relax it to an SDP, but he has a better idea). Instead, he notes that we can leverage the compact support of to evaluate candidate phases of
-transforms of and have no common roots. Amazingly, spectral independence completely characterizes VPR uniqueness, at least in the case where the supports of and lie in a common contiguous half of the entries. In this case, reconstruction can be implemented by a polarization trick. Noise robustness seems to be a much harder problem. To address this, Boaz considers a reasonable noise model for his application, and notes that the likelihood function is not convex and thus difficult to maximize (he could relax it to an SDP, but he has a better idea). Instead, he notes that we can leverage the compact support of to evaluate candidate phases of  . Specifically, we can multiply by any given candidate phases and take the inverse Fourier transform, and then see if the result is “close” to having compact support. This closeness corresponds to a convex functional such that the true signal is necessarily the unique minimum (in the noiseless case) provided and are spectrally independent. Unfortunately, the region of optimization is not convex, but Boaz relaxes this region with no problem. Now he can determine the support of the signals by iteratively solving with different guesses for the support size, and comparing the results with a penalty term (which he needs, since otherwise the fits improve monotonically with the support size due to overfitting). Boaz concluded his talk by pointing out how performance compares to the SDP relaxation of the likelihood function (he gets much smaller estimate error after far fewer iterations), and how his approach also works for exponentially decaying signals (which are close to having compact support). VPR certainly seems to be a fruitful version of the phase retrieval problem (much like the version I tend to focus on), and I’m interested to see what else comes from that side of the house.
. Specifically, we can multiply by any given candidate phases and take the inverse Fourier transform, and then see if the result is “close” to having compact support. This closeness corresponds to a convex functional such that the true signal is necessarily the unique minimum (in the noiseless case) provided and are spectrally independent. Unfortunately, the region of optimization is not convex, but Boaz relaxes this region with no problem. Now he can determine the support of the signals by iteratively solving with different guesses for the support size, and comparing the results with a penalty term (which he needs, since otherwise the fits improve monotonically with the support size due to overfitting). Boaz concluded his talk by pointing out how performance compares to the SDP relaxation of the likelihood function (he gets much smaller estimate error after far fewer iterations), and how his approach also works for exponentially decaying signals (which are close to having compact support). VPR certainly seems to be a fruitful version of the phase retrieval problem (much like the version I tend to focus on), and I’m interested to see what else comes from that side of the house.
Next, Paul Hand presented a recent result of his regarding PhaseLift. Specifically, he notes that in many cases, the trace minimization of PhaseLift is performed over a singleton set, and so the semidefinite program is overkill – you just need to find the unique point in the feasibility region. Since this region is precisely the intersection of the positive semidefinite cone with the shifted nullspace corresponding to the intensity measurements, this leads to something particularly interesting: phase retrieval can actually be solved using alternating projections. To be clear, alternating projections is perhaps the biggest punching bag of modern phase retrieval because it’s so ad hoc. Well, at least the version of alternating projections that was originally used: Given measurements 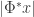 , project onto the range of
, project onto the range of 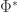 , correct the magnitudes of the entries, and repeat. Here, you alternate between projecting onto a subspace and onto a Cartesian product of circles, and this iteration notoriously fails to work. On the other hand, Paul shows that alternating projections can work just fine – provided the one set you project onto is the positive semidefinite cone, and the other is the shifted nullspace corresponding to the intensity measurements (both of which are convex, and therefore find convergence guarantees).
, correct the magnitudes of the entries, and repeat. Here, you alternate between projecting onto a subspace and onto a Cartesian product of circles, and this iteration notoriously fails to work. On the other hand, Paul shows that alternating projections can work just fine – provided the one set you project onto is the positive semidefinite cone, and the other is the shifted nullspace corresponding to the intensity measurements (both of which are convex, and therefore find convergence guarantees).
Yang Wang was next, and he talked about about a couple of things. First, he surveyed what is currently known about minimal frames for phase retrieval. For example, if  denotes the smallest number of intensity measurements which lend injectivity for
denotes the smallest number of intensity measurements which lend injectivity for 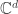 , then by Bodmann and Hammen’s result,
, then by Bodmann and Hammen’s result,  , and furthermore, Heinosaari, Mazzarella and Wolf also gives us that
, and furthermore, Heinosaari, Mazzarella and Wolf also gives us that  . Also, if denotes the smallest number such that intensity measurements lend uniqueness for almost every vector in , then
. Also, if denotes the smallest number such that intensity measurements lend uniqueness for almost every vector in , then 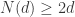 by Flammia, Silberfarb and Caves, while
by Flammia, Silberfarb and Caves, while  by Balan, Casazza and Edidin, although Yang says he isn’t completely convinced by the proof of the latter (perhaps I’ll have to investigate it further). Yang also indicated that
by Balan, Casazza and Edidin, although Yang says he isn’t completely convinced by the proof of the latter (perhaps I’ll have to investigate it further). Yang also indicated that  is the smallest number of holography-type measurements that uniquely determine a signal in , and in this case, is completely determined (not just up to global phase). The second half of his talk was devoted to the polarization-based multi-scale measurement ensemble and reconstruction algorithm that he presented in Vienna. This time, Matt Fickus commented at the end of the talk that Fourier-type measurements could be used to speed up reconstruction from
is the smallest number of holography-type measurements that uniquely determine a signal in , and in this case, is completely determined (not just up to global phase). The second half of his talk was devoted to the polarization-based multi-scale measurement ensemble and reconstruction algorithm that he presented in Vienna. This time, Matt Fickus commented at the end of the talk that Fourier-type measurements could be used to speed up reconstruction from 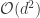 operations to something like
operations to something like 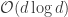 – this is screaming fast compared to semidefinite programming (and the constant is much smaller – like
– this is screaming fast compared to semidefinite programming (and the constant is much smaller – like  ).
).
The last talk was given by the resident organizer of the workshop – Radu Balan. In the complex case, very little is known about what it means for phase retrieval to be stable, and in his talk, Radu presented some of work that helps to close this gap. Specifically, assuming Gaussian noise on the intensity measurements 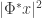 , Radu determines the corresponding Fisher information matrix, and according to the theory of Cramer-Rao lower bounds, this matrix is used to bound the covariance of any unbiased estimator of the signal . Here, the bound is rather subtle because the information matrix is actually not invertible (since “so much” phase is lost in the complex case), but Radu plays a trick with submatrices to find the proper bound. He also identifies certain properties of the information matrix with injectivity, and in a way, this illustrates that his notion of stability is some sort of numerical version of the more algebraic notion of injectivity. He concluded his talk by discussing an optimization procedure for maximum likelihood estimation. Much of this is described in a recent paper of his, and the Cramer-Rao analysis in the complex case is also available in this paper (we had some overlaps in our research – great minds think alike!).
, Radu determines the corresponding Fisher information matrix, and according to the theory of Cramer-Rao lower bounds, this matrix is used to bound the covariance of any unbiased estimator of the signal . Here, the bound is rather subtle because the information matrix is actually not invertible (since “so much” phase is lost in the complex case), but Radu plays a trick with submatrices to find the proper bound. He also identifies certain properties of the information matrix with injectivity, and in a way, this illustrates that his notion of stability is some sort of numerical version of the more algebraic notion of injectivity. He concluded his talk by discussing an optimization procedure for maximum likelihood estimation. Much of this is described in a recent paper of his, and the Cramer-Rao analysis in the complex case is also available in this paper (we had some overlaps in our research – great minds think alike!).

Thank you very much for the summary.
As a Newbie, I am permanently searching online for articles that can benefit me. Thank you