Soledad Villar recently posted her latest paper on the arXiv (joint work with Afonso Bandeira, Andrew Blumberg and Rachel Ward). This paper reduces an instance of cutting-edge data science (specifically, shape matching and point-cloud comparison) to a semidefinite program, and then investigates fast solvers using non-convex local methods. (Check out her blog for an interactive illustration of the results.) Soledad is on the job market this year, and I read about this paper in her research statement. I wanted to learn more, so I decided to interview her. I’ve lightly edited her responses for formatting and hyperlinks:
DGM: How were you introduced to this problem? Do you have any particular applications of shape matching or point-cloud comparison in mind with this research?
SV: This problem was introduced to me by Andrew Blumberg in the context of topological data science. Andrew is an algebraic topologist who is also interested in applications, in particular in computational topology. There is a vast literature on the registration problem for 3d shapes and surfaces, but usually they are tailored to the geometric properties of the space and rely on strong geometry assumptions. Our goal was to study this problem in an abstract setting, that could have potential impact in spaces with unusual geometry. In particular we are thinking of spaces of phylogenetic trees, protein-protein interaction data, and text processing. We don’t have experimental results for those problems yet but we are working on it.
A reason why it is so hard to obtain meaningful results for these “real data” problems is that it is hard to validate whether the method produces a meaningful result. A simple way for a mathematician like me to validate the performance of our methods and algorithms is to compare with problems where the ground truth solution is known (like the teeth classification and shape matching), and this is what we did in the paper.
For future scientific applications, I’m working with Bianca Dumitrascu, who is a graduate student in computational biology at Princeton. Bianca works with large datasets of protein-protein interaction information. She has the intuition that the existence of isometries between protein interaction measurements in different biological systems should be correlated with similar roles between corresponding proteins. However such behavior is very hard to test in real data because of scalability issues, the large amount of noise present in the data, and the lack of a theoretical ground truth in most cases.
DGM: Do you have any intuition for why your polynomial-time lower bound on Gromov-Hausdorff distance satisfies the triangle inequality?
SV: The intuitive answer: I think this is a phenomenon aligned with the “data is not the enemy” philosophy. The Gromov-Hausdorff distance is NP-hard in the worst case, but it is actually computable in polynomial time for a generic set of metric spaces. Since in the small scale our relaxed distance coincides with the Gromov-Hausdorff distance, then intuitively we could expect that it is actually a distance (and therefore satisfies triangle inequality).
The practical answer: Considering the relations that realize 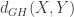

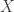
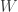


DGM: You proved that generic finite metric spaces
SV: I think tightness occurs for relatively large perturbations of the isometric case provided that the data is well conditioned. However, in an extreme case, if all pairwise distances are the same, then the solution of the semidefinite program is not unique and therefore tightness will not occur. When studying the distance from the topological point of view, a result of the form “there exists a local neighborhood such that the distances coincide” is relevant. From an applied mathematical perspective, it would interesting to quantify for how large perturbations the semidefinite program is tight. The techniques I know for obtaining such a result rely on the construction of dual certificates. The dual certificates I managed to construct also had a dependency on 


DGM: How frequently does your local method GHMatch recover the Gromov-Hausdorff distance in practice? Is there a way to leverage the smallest eigenvector of
SV: The algorithm GHMatch often gets stuck in local minima. In many non-convex optimization algorithms, good initialization is good enough to guarantee convergence to a global optimal after some steps of gradient descent. However our optimization problem has non-negative constraints which makes it significantly harder because the variable