Last week, I attended this conference in Berlin, and much like the last CSA conference, it was very nice. This year, most of the talks followed one of three themes:
- Application-driven compressed sensing
- Quadratic or bilinear problems
- Clustering in graphs or Euclidean space
Examples of application-driven CS include theoretical results for radar-inspired sensing matrices and model-based CS for quantitative MRI. Readers of this blog are probably familiar with the prototypical quadratic problem (phase retrieval), and bilinear problems include blind deconvolution and self-calibration. Recently, I have blogged quite a bit about clustering in Euclidean space (specifically, k-means clustering), but I haven’t written much about clustering in graphs (other than its application to phase retrieval). For the remainder of this entry, I will discuss two of the talks from CSA2015 that covered different aspects of graph clustering.
— Background —
Consider a random graph following the inhomogeneous Erdos–Renyi model  . Here, vertices
. Here, vertices  and
and  share an edge with probability
share an edge with probability  , independently of the other edges. For example, in the stochastic block model, the vertices are partitioned into
, independently of the other edges. For example, in the stochastic block model, the vertices are partitioned into 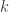 communities, and then equals either
communities, and then equals either 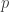 or
or  according to whether and are members of the same community:
according to whether and are members of the same community:

(Figures courtesy of Afonso Bandeira.) Now suppose you receive an instance of this random model, but you are not given the partition into communities (or or ):

The goal of community detection is to estimate the communities from this data. Consider the special case where there are 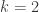 communities, each of size exactly
communities, each of size exactly 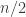 . It turns out that if and scale like
. It turns out that if and scale like 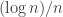 , then exact community recovery is possible, and the phase transition is well understood. (Intuitively, this makes sense since the signal is given in the form of connectivity, and is the ER threshold for connectivity.) If and scale like
, then exact community recovery is possible, and the phase transition is well understood. (Intuitively, this makes sense since the signal is given in the form of connectivity, and is the ER threshold for connectivity.) If and scale like  , then exact recovery is impossible, but there’s also a well-understood phase transition for when you can estimate better than random guessing. (Here, matches the ER threshold for a giant component.)
, then exact recovery is impossible, but there’s also a well-understood phase transition for when you can estimate better than random guessing. (Here, matches the ER threshold for a giant component.)
Given a graph with adjacency matrix 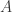 , consider the normalized graph Laplacian:
, consider the normalized graph Laplacian:
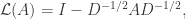
where  denotes the diagonal matrix whose
denotes the diagonal matrix whose 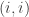 th entry is the degree of the th vertex. The eigenvalues of
th entry is the degree of the th vertex. The eigenvalues of  lie between 0 and 2, and it’s easy to verify that
lie between 0 and 2, and it’s easy to verify that 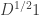 is an eigenvector with eigenvalue
is an eigenvector with eigenvalue 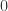 . The dimension of the null space equals the number of connected components in the graph, and in fact, the null space is spanned by vectors which are supported on each of the components. Intuitively, the graph is well connected if the second-smallest eigenvalue is large (as exemplified by Ramanujan graphs), and if this eigenvalue is small but the third-smallest is large, then your graph is essentially two well-connected components with a few edges added to connect the two (much like the stochastic ball model with large and small). In this case, the second eigenvector is “close” to being in the null space, and so the two well-connected components can be determined by finding a couple of localized vectors that span the span of the first two eigenvectors (in practice, it suffices to take the sign pattern of the second eigenvector). This is called spectral clustering.
. The dimension of the null space equals the number of connected components in the graph, and in fact, the null space is spanned by vectors which are supported on each of the components. Intuitively, the graph is well connected if the second-smallest eigenvalue is large (as exemplified by Ramanujan graphs), and if this eigenvalue is small but the third-smallest is large, then your graph is essentially two well-connected components with a few edges added to connect the two (much like the stochastic ball model with large and small). In this case, the second eigenvector is “close” to being in the null space, and so the two well-connected components can be determined by finding a couple of localized vectors that span the span of the first two eigenvectors (in practice, it suffices to take the sign pattern of the second eigenvector). This is called spectral clustering.
— Recovering hidden structures in sparse networks —
Roman Vershynin gave a talk based on two papers (one and two). Here, we will discuss the first paper. Suppose you want to perform spectral clustering to solve community detection under the stochastic block model. In order for this to work, you might expect it to necessarily work for the “expected graph,” whose normalized Laplacian is easily computed as

where  denotes the vector which is +1 for vertices in the first community and -1 in the second. Indeed, the second eigenvector of this expected Laplacian is , as desired. In order for this behavior to be inherited by the random graph, we would like its eigenstructure to be close to its expectation. By the Davis–Kahn theorem, it suffices for to be close to
denotes the vector which is +1 for vertices in the first community and -1 in the second. Indeed, the second eigenvector of this expected Laplacian is , as desired. In order for this behavior to be inherited by the random graph, we would like its eigenstructure to be close to its expectation. By the Davis–Kahn theorem, it suffices for to be close to  in the spectral norm. As such, we seek some sort of concentration phenomenon.
in the spectral norm. As such, we seek some sort of concentration phenomenon.
It is known that the Laplacian exhibits such concentration in the “dense” regime where the ‘s scale like . On the other hand, the “sparse” regime (where the scaling is ) is flooded with isolated vertices, and so all of these components thwart the success of spectral clustering (let alone Laplacian concentration, which would imply success). A similar problem was encountered in the development of PageRank: Since the internet has many isolated pages, a random surfer would fail to reach these pages, and so the surfer model is modified to allow for a small probability of “getting bored” (in which case the surfer visits a webpage drawn uniformly at random). This modification to the surfer model can be interpreted as a modification to the graph, where every pair of vertices receives an additional edge with appropriately small weight. If the added weights are selected appropriately, it turns out that this regularization allows for concentration in the Laplacian:
Theorem (Theorem 1.2 in Le–Vershynin). Pick  and define the “regularization”
and define the “regularization”  . Then
. Then

with high probability.
The proof of this result amounts to iteratively finding a decomposition of the adjacency matrix using a neat Grothendieck-type inequality:
Theorem (Grothendieck–Pietsch factorization). Let  be a
be a  real matrix and
real matrix and 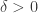 . Then there exists a
. Then there exists a 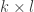 submatrix
submatrix 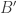 of with
of with 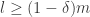 such that
such that

By iteratively applying this inequality, one may isolate portions of the matrix which are sufficiently dense (from a spectral perspective) to concentrate “for free,” and then the remaining sparse portions (which are more significantly impacted by regularization) may be estimated by Riesz–Thorin interpolation.
Some open problems along these lines:
- Le–Vershynin regularize with
 , but what is the optimal parameter?
, but what is the optimal parameter?
- Can
 be replaced by
be replaced by  ?
?
- Does regularization find applications with more general random matrices?
(For the last problem, regularization does bear some resemblance to the truncated spectral initialization of the new Wirtinger Flow paper.)
— Phase transitions in semidefinite relaxations —
Andrea Montanari also gave a talk based on two papers (one and two), and we will discuss the first one. This talk investigated the advantages that SDP clustering has over spectral methods. Given a random graph of average degree 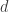 , consider the following SDP:
, consider the following SDP:

Clearly, the value of this program is a function of . The main result of the first paper is that thresholding this value will typically distinguish stochastic block model graphs with edge probabilities 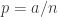 and
and  from ER graphs with constant probability
from ER graphs with constant probability  when
when

For reference, it is known that there is not enough signal for any test to succeed when  . By comparison, performing spectral clustering to the regularized graph will work when
. By comparison, performing spectral clustering to the regularized graph will work when 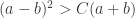 for some unreported constant
for some unreported constant  (see equation (1.7) in Le–Vershyni).
(see equation (1.7) in Le–Vershyni).
To prove this result, one must find upper and lower bounds on 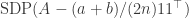 in the cases where comes from the stochastic block model and the ER model, respectively. To estimate this value, Montanari and Sen use a Lindeberg-type method to pass the random models to analogous Gaussian models, for which the desired tail bounds are more accessible.
in the cases where comes from the stochastic block model and the ER model, respectively. To estimate this value, Montanari and Sen use a Lindeberg-type method to pass the random models to analogous Gaussian models, for which the desired tail bounds are more accessible.
I personally find the Lindeberg method to be quite interesting. The main idea is that, if  is smooth,
is smooth, 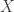 is a random vector with iid entries of mean 0 and variance 1, and
is a random vector with iid entries of mean 0 and variance 1, and 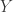 is a random vector with iid Gaussian entries of mean 0 and variance 1, then
is a random vector with iid Gaussian entries of mean 0 and variance 1, then  is close to
is close to 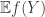 . In fact, the entries of need not be independent, but rather exchangeable (see Theorem 1.2 in Chatterjee). This method was recently leveraged by Oymak and Tropp to study a particularly general class of random projections.
. In fact, the entries of need not be independent, but rather exchangeable (see Theorem 1.2 in Chatterjee). This method was recently leveraged by Oymak and Tropp to study a particularly general class of random projections.
In order to leverage Lindeberg to convert to Gaussian, we need a smooth function, but considering how pointy the PSD cone is, it comes as no surprise that  fails to be sufficiently smooth. To remedy this, Montanari and Sen first define
fails to be sufficiently smooth. To remedy this, Montanari and Sen first define
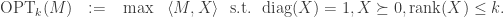
Then each in the feasibility region can be expressed as a Gram matrix  , where
, where  and each column has unit 2-norm. Of course,
and each column has unit 2-norm. Of course,  , and a symmetric version of Grothendieck’s inequality, gives that
, and a symmetric version of Grothendieck’s inequality, gives that  . Montanari and Sen generalize this inequality to show that
. Montanari and Sen generalize this inequality to show that  for each .
for each .
However,  is still not a smooth function, but it can be approximated by a smooth function by leveraging ideas from statistical mechanics. Indeed, consider the log-partition function
is still not a smooth function, but it can be approximated by a smooth function by leveraging ideas from statistical mechanics. Indeed, consider the log-partition function
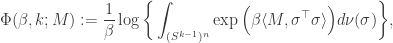
where 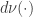 denotes the uniform measure over the product of spheres
denotes the uniform measure over the product of spheres  . As
. As 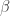 gets large, the integrand becomes increasingly peaky at the maximizer of
gets large, the integrand becomes increasingly peaky at the maximizer of 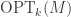 , and so the log approaches
, and so the log approaches  . As such,
. As such, 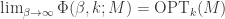 , suggesting that one may pick so as to juggle smoothness and approximation.
, suggesting that one may pick so as to juggle smoothness and approximation.

An interesting post by me, related to compressed sensing : https://rajeshd007.wordpress.com/2016/01/19/a-concept-in-classical-fourier-analysis-and-its-similarity-to-compressed-sensing-using-minimum-total-variation/