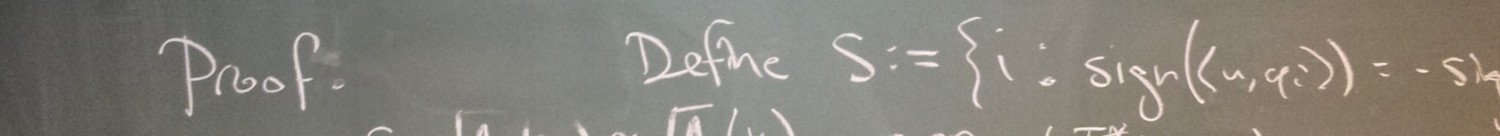Jameson Cahill and I recently posted a new paper on the arXiv that we’re pretty excited about. Suppose you want to do compressed sensing with L1 minimization. That is, you get  for some nearly
for some nearly 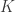 -sparse vector
-sparse vector 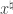 and some noise
and some noise  satisfying
satisfying  , and then you attempt to reconstruct by taking
, and then you attempt to reconstruct by taking
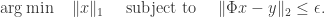
One of the main results of compressed sensing is that the optimizer 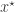 of the above program satisfies
of the above program satisfies
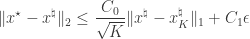
provided 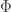 satisfies the
satisfies the 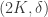 -restricted isometry property (RIP) for some
-restricted isometry property (RIP) for some  . Here,
. Here, 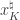 denotes the best -term approximation of , and so
denotes the best -term approximation of , and so  captures how close is to being -sparse. Jameson and I wondered if RIP was necessary to enjoy this uniformly stable and robust performance (uniform in the sense that the fixed matrix works for all simultaneously, stable because we don’t require to be exactly -sparse, and robust because we allow noise). In our paper, we completely characterize the matrices that offer this performance, and we show that RIP matrices form a strict subset.
captures how close is to being -sparse. Jameson and I wondered if RIP was necessary to enjoy this uniformly stable and robust performance (uniform in the sense that the fixed matrix works for all simultaneously, stable because we don’t require to be exactly -sparse, and robust because we allow noise). In our paper, we completely characterize the matrices that offer this performance, and we show that RIP matrices form a strict subset.
Before introducing the property, consider the following illustration of a high-dimensional L1 ball:

(This is taken from slides of Roman Vershynin; forgive the lack of symmetry that you’d expect in an L1 ball.) While this depiction is obviously not convex, it captures an important property of high-dimensional convex sets: They are composed of a round bulk, which accounts for the vast majority of the volume, and of a few outliers (the extreme points), which contribute a few long tentacles of negligible volume. In the case of the L1 ball, the extreme points correspond to sparse vectors. In order for to distinguish any pair of -sparse vectors, we require its nullspace to avoid all  -sparse vectors. One way to enforce this is to require the nullspace
-sparse vectors. One way to enforce this is to require the nullspace  to intersect the L1 ball with sufficiently small width, since this in turn would imply that every -sparse tentacle is avoided:
to intersect the L1 ball with sufficiently small width, since this in turn would imply that every -sparse tentacle is avoided:

As Kashin and Temlyakov remark, this so-called width property is equivalent to having uniform stability in the L1 minimizer when 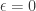 . Furthermore, by Milman’s low M* estimate, a randomly selected nullspace will satisfy the width property provided its dimension is appropriately small (“a random subspace passes through the bulk”). This is one way to explain why random matrices perform so well in compressed sensing.
. Furthermore, by Milman’s low M* estimate, a randomly selected nullspace will satisfy the width property provided its dimension is appropriately small (“a random subspace passes through the bulk”). This is one way to explain why random matrices perform so well in compressed sensing.
So how does one account for noise? To do this, our paper introduces the robust width property: We say satisfies the 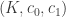 -robust width property (RWP) if
-robust width property (RWP) if

for every  such that
such that  . Our main result says that having uniformly stable and robust reconstruction with constants ,
. Our main result says that having uniformly stable and robust reconstruction with constants , 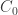 and
and 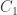 is equivalent to having -RWP with
is equivalent to having -RWP with  and
and  (we lose a factor of 2 or 4 in both directions of the equivalence). In the special case where the rows of are orthonormal, RWP means that every slight perturbation of the nullspace satisfies the width property (here, perturbation is measured in the gap metric, and
(we lose a factor of 2 or 4 in both directions of the equivalence). In the special case where the rows of are orthonormal, RWP means that every slight perturbation of the nullspace satisfies the width property (here, perturbation is measured in the gap metric, and  bounds the size of the acceptable perturbations). Also observe the contrapositive of RWP: that
bounds the size of the acceptable perturbations). Also observe the contrapositive of RWP: that  for every “nearly -sparse” , that is for every satisfying
for every “nearly -sparse” , that is for every satisfying 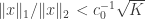 ; this is reminiscent of the lower RIP bound. Finally, in the last section of the paper, we use ideas from this paper to find a matrix which satisfies RWP, but not RIP, meaning the containment is strict.
; this is reminiscent of the lower RIP bound. Finally, in the last section of the paper, we use ideas from this paper to find a matrix which satisfies RWP, but not RIP, meaning the containment is strict.
In recent years, several instances of compressed sensing have emerged, for example, in which one seeks weighted sparsity, block sparsity, gradient sparsity, or low-rank matrices. For each of these instances, there is a convex program which has been proven to provide uniformly stable and robust reconstruction. Our paper provides a general robust width property which captures all of these instances simultaneously.